Introduction
Par is affectionately named after the most bemusing connective of linear logic: ⅋, pronounced “par”. That’s because Par is based directly on (classical) linear logic, as an experiment to see where this paradigm can take us.
Jean-Yves Girard — the author of linear logic, and System F, among other things — wrote on the page 3 of his first paper on linear logic:
The new connectives of linear logic have obvious meanings in terms of parallel computation, especially the multiplicatives.
This was in 1987. In hindsight, it wasn’t that obvious.
Par is an attempt to take that idea seriously — to turn linear logic into a practical programming language.
Why Par?
Based on linear logic, Par has a linear type system. That’s close to what you know from Rust: linear values have a single owner and are moved instead of copied. But unlike in Rust, linear values cannot be dropped. Instead, they have to be consumed according to their type.
This unlocks something special: channels that may only be consumed by sending. Now the receiver has a new guarantee — it no longer has to consider the sender forgetting to communicate.
As a consequence, concurrent communication is as transparent and composable in Par as calling functions. Together with Par’s imposition of a tree-like communication structure — ruling out deadlocks — a new promising way of building concurrent applications arises.
But, Par isn’t just a concurrent language.
Classical linear logic is a beast, and a powerful one at that. Par absorbs all this power into its own expressivity. With duality, session types, and a rich set of concepts all mapping to logical connectives, multiple paradigms emerge naturally:
- Functional programming with side-effects via linear handles.
- A unique object-oriented style, where interfaces are just types and implementations are just values.
- An implicit concurrency, where execution is non-blocking by default.
Multi-paradigm language often burden its users with multiple ways to solve the same problem.
But, somewhat surprisingly, we found that in Par, any single problem tends to have a single best solution. That solution may be functional, object-oriented, a mix of those, or something else entirely.
Whichever one it is, it always puts a new puzzle into something there underneath: the Par way.
Orthogonality goes wide, not deep
Par doesn’t have dependent types, metaprogramming, higher-order kinds, or a macro system. Instead of going deeper into complexity, Par goes wider.
Its design focuses on small, composable ideas. For Par, it’s not that important to have a small number of features. What’s important is that each feature is small, and covers something no other feature does.
Most of those ideas are taken directly from classical linear logic. Every type corresponds to a logical connective. Even recursion! This has two consequences:
- Everything fits together. Almost any combination of features has a meaningful use.
- Everything is a little different. For better or worse, Par is one of its kind.
The former is great. The latter means Par might feel like learning programming all over again. Will that be worthwhile? We’re going to have to find out.
An ambitious stride towards totality
As if session types and concurrency weren’t enough, Par also aims to be total.
That means:
- No exceptions or panics.
- No deadlocks. Par imposes a structure where deadlocks are impossible to express.
- No accidental non-termination. By default, recursion and corecursion are checked to prevent infinite loops.
No infinite loops? How do I write a web server or an event loop? Don’t worry, that’s not infinite loops, that’s what we call corecursion. It’s covered thoroughly by iterative types with totality ensuring they always advance to their next step.
At the moment, the system isn’t powerful enough to capture some more complex algorithms, so there’s an escape hatch. But, the eventual goal is to get rid of it.
Let’s dive in!
Par is a language in active development. It’s not production-ready — but it’s expressive, and ready to be explored.
If you’re curious about what programming can look like when guided by logic — turn the page.
Getting Started
Let’s install the Par programming language.
At the moment, there are no pre-built binaries, or releases, so we’ll have to build it from source.
1. Install Rust and Cargo
Par is written in Rust. To be able to build it from source, we’ll need to install Rust and its build tool, called Cargo.
The easiest way to do that is via rustup. The website instructs:
Run the following in your terminal, then follow the onscreen instructions.
$ curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
2. Clone Par’s repository
The next step is to obtain Par’s source code. That is located on GitHub. Clone it locally by running the following in your terminal:
$ git clone https://github.com/faiface/par-lang
3. Build and install Par’s CLI tool
Navigate to the newly created directory:
$ cd par-lang
Then install the executable using Cargo:
$ cargo install --path .
This may take a while as Rust downloads and builds all the dependencies.
This installs the par command.
4. Create a package
A new par command should now be available in your terminal. It may be necessary
to restart the terminal for it to appear.
Let’s create a fresh package:
$ par new hello_par
$ cd hello_par
This creates:
hello_par/
Par.toml
src/
Main.par
The generated src/Main.par is a tiny runnable Par program. You can run it with:
$ par run
And you can type-check the package without running it:
$ par check
5. Browse the docs
Par comes with a built-in docs browser:
$ par doc
This command is useful in three different situations:
- Outside any package,
par docshows the documentation for the built-in packages. - Inside a package,
par docshows the current package together with its dependencies. - For a remote package,
par doc --remote github.com/faiface/par-cancellablelets you inspect a package without manually adding it as a dependency.
6. Open the playground
The playground is a great way to experiment with code and interact with values through the playground’s automatic UI:
$ par playground
And the playground should appear:
If all is good, turn the page and let’s get into the language itself!
In case of problems, head over to our Discord, we’ll try and help.
Basic Program Structure
Before we start writing our own package, it’s helpful to see Par in action in the playground.
Let’s open it:
$ par playground
Press Compile, then open the Run menu and pick a built-in definition from core.
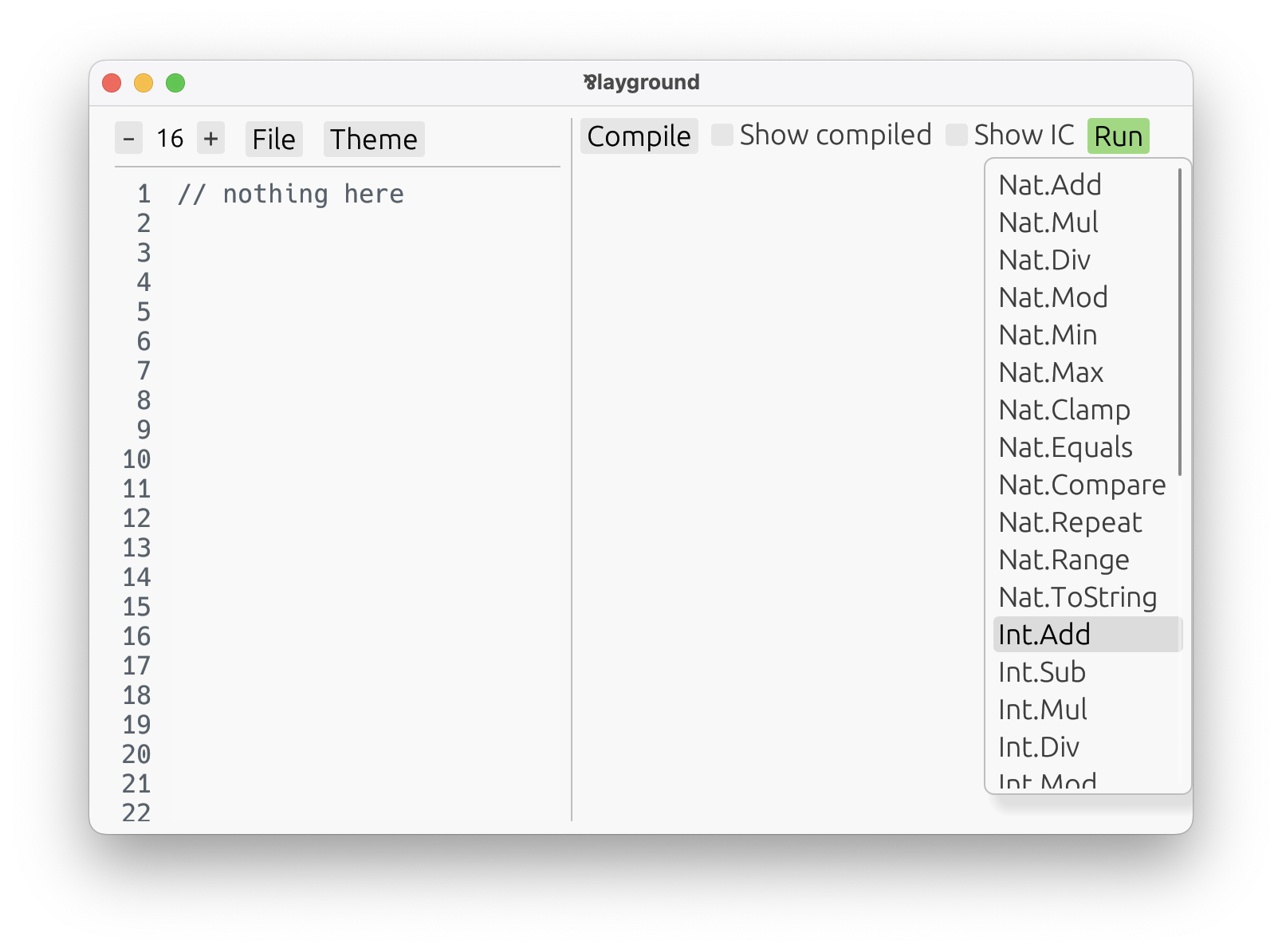
As a first example, choose one of the built-in numeric helpers from the core package. Int.Mod
computes the non-negative remainder of an integer modulo a natural number:
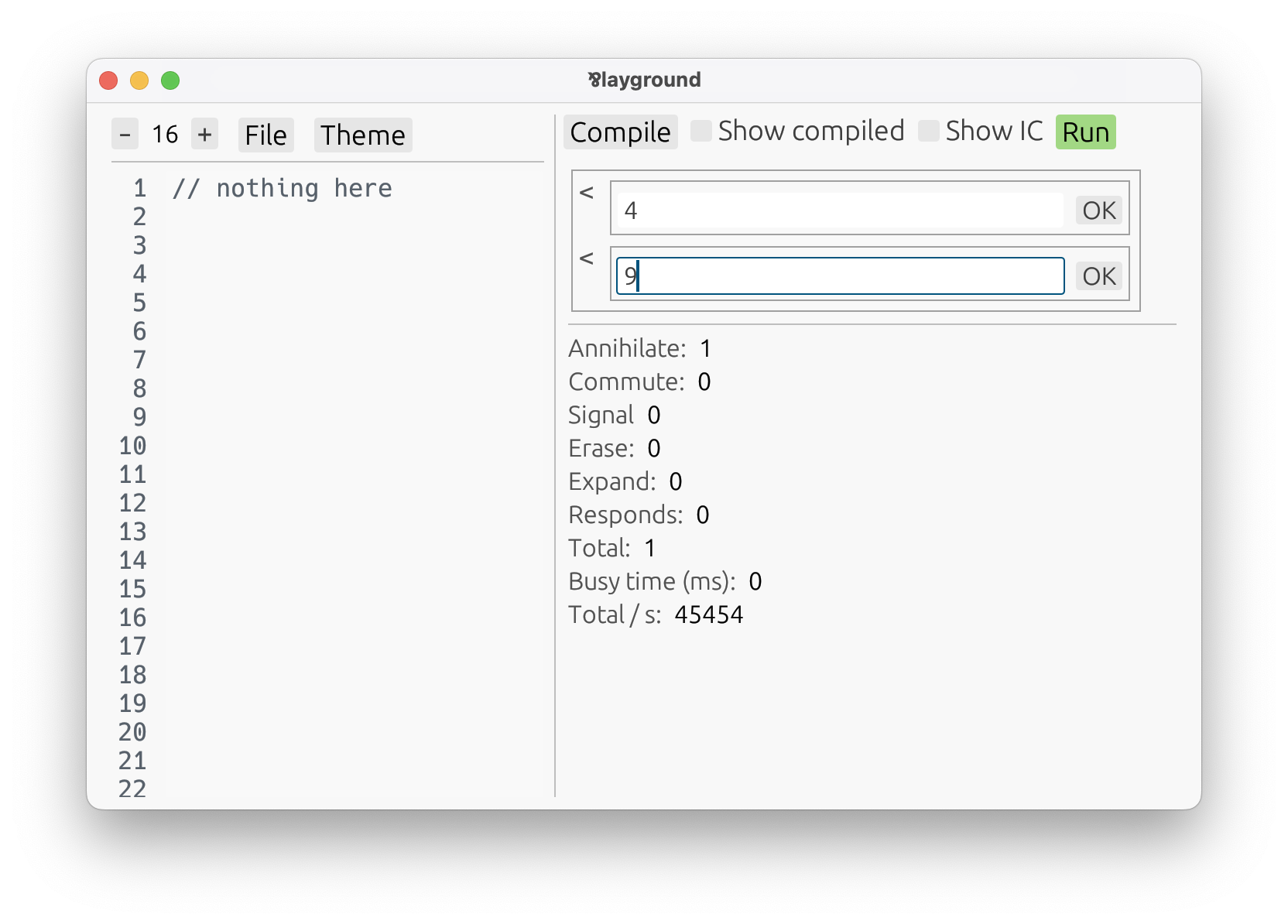
An automatic UI shows up, telling us to input the arguments expected by the selected definition. After confirming them, we get a result:
This automatic UI is a feature of the playground, not of the Par language itself. Nobody made a
specific interface for Int.Mod. Instead, the playground looked at its type — here, a function from
two numbers to a number result — and generated a small interface for interacting with it.
That makes the playground a nice way to explore built-in definitions, and later your own definitions too.
On the next page, we’ll create a fresh package and look at what actually lives inside a Par module.
Definitions & Declarations
Let’s keep working with the package created by par new.
Its src/Main.par file starts like this:
module Main
There may also be imports above the rest of the code, but we’re going to ignore those for a moment and focus only on what comes after them.
At the top level of a Par module, you write:
- definitions
- declarations
- type definitions
These define global names that can be used throughout the module, an unlimited number of times.
In a fresh package, par run looks for the Main definition in the Main module, that is
Main.Main.
So:
par runmeansMain.Mainpar run Main.Othermeans theOtherdefinition in theMainmodule
Once there are more modules, the same idea extends to paths such as par run util/Parse.Program.
We’ll come back to that in the next section.
Because of Par’s linear type system, local variables may be required to be used exactly once. That is if they have a linear type. Global definitions can be used any number of times regardless of their type.
Par has a simple naming rule:
- Global names start with an upper-case letter. That is global types, functions, and so on.
- Local names start with a lower-case letter, or
_. That includes local variables, function parameters, and type variables in generic functions.
While global names can be used throughout their module, there is an important restriction!
❗ Cyclic usages are forbidden! Both in types, and in definitions.
That means that if a type
Aliceuses a typeBob, thenBobcan’t useAlice. Same for functions, and other definitions. In fact,Alicecan’t useAliceeither!
This apparently mad restriction has important motivations, and innovative remedies.
The motivation is Par’s ambitious stride towards totality — which means preventing infinite loops.
Unrestricted recursion is a source of infinite loops, and while that can be partially remedied by totality checkers, such as in Agda, Par chooses a different approach. That is outlawing unrestricted recursion, and instead relying on more principled ways to achieve cyclic behavior, including what’s usually achieved by mutual recursion.
The remedies come in the form of these more principled ways. Fortunately, they don’t just replace the familiar recursion by clunkier mechanisms, they bring their own perks.
Naive recursion on the term level (like in functions) is replaced by a powerful,
universal looping mechanism, called begin/loop. It’s a single tool usable for:
- Recursive reduction. Analyzing lists, trees, or even files.
- Iterative construction. Those are objects that can be interacted with repeatedly.
- Imperative-looking loops in process syntax.
Naive recursion in types is replaced by anonymous recursive and iterative (corecursive) types.
Definitions
Global values (including functions) are defined at the top level starting with the keyword def,
followed by an upper-case name, an = sign, and an expression computing the value.
module Main
def MyNumber = 7
In this case, Par is able to infer the type of MyNumber as Nat
(a natural number), so no type annotation is needed. Often, a type annotation is needed, or wanted.
In those cases, we can add it using a colon after the name:
def MyName: String = "Michal"
Declarations
Sometimes a type is longer and a definition becomes busy and hard to read with it.
For example, here’s a simple function adding up all the numbers in a list:
def SumList: [List<Int>] Int = [list] list.begin.case {
.end! => 0,
.item(x) xs => x + xs.loop,
}
The code uses many concepts that will be covered later, so only focus on the parts you know: def,
:, and =. (You can run it in the playground, though!)
In such a case, the type annotation can be extracted into a separate declaration. A declaration
starts with the keyword dec, followed by the name we want to annotate, a colon, and a type.
dec SumList : [List<Int>] Int
def SumList = [list] list.begin.case {
.end! => 0,
.item(x) xs => x + xs.loop,
}
That’s much better!
Declarations may be placed anywhere in a file, so feel free to put them all on top, or keep them close to their corresponding definitions.
Type Definitions
Par has a structural type system. While many languages offer multiple forms of type definitions
— for example, Rust has struct, enum, and more — Par only has one: type aliases.
With recursive and iterative types being anonymous, Par has no issue treating types as their shapes, instead of their names. In fact, type definitions are completely redundant in Par. Every usage of a global type (with the exception of the primitives) can be replaced by its definition, until no definitions are used.
Actually, all definitions are redundant in Par. However, programming without them would be quite tedious.
To give a name to a type, use the type keyword at the top level, followed by an upper-case name,
an = sign, and a type to assign to it.
type MyString = String
MyString is now equal to String and can be used wherever String can.
A more useful example:
type StringBuilder = iterative choice {
.build => String,
.add(String) => self,
}
This particular type is a part of the built-in functionality, under the name
String.Builder.
That’s an iterative choice type, something we will learn later. It’s an object that can be interacted with repeatedly, choosing a branch (a method) every time.
While we could paste the entire definition every time we would use this StringBuilder, it’s quite
clear why we wouldn’t want to do that.
Generic types
A type definition may include generic type parameters, turning it into a formula that can be instantiated with any types substituted for the parameters.
The type parameters are specified in a comma-separated list inside angle brackets right after the type name. The parameters are local names, so they must be lower-case.
For example, the built-in List type has one type parameter:
type List<a> = recursive either {
.end!,
.item(a) self,
}
That’s a recursive either type, also something we will
learn later. In this case, it defines a finite, singly-linked list of items of type a.
To use a generic type, we append a comma-separated list of specific type arguments enclosed in angle brackets after the type’s name.
type IntList = List<Int>
The resulting type is obtained by replacing each occurrence of each type variable by its corresponding type argument. So, the above is equal to:
type IntListExpanded = recursive either {
.end!,
.item(Int) self,
}
Now that we know what goes inside a module, let’s zoom out and look at packages, modules, imports, and exports.
Packages & Modules
So far, we’ve focused on the contents of one module file. That’s a good place to start, but real Par programs live in packages, and packages are made of modules.
The hierarchy looks like this:
- A program or a library is a package.
- A package contains modules.
- A module contains type definitions, declarations, and definitions.
Let’s now look at how those pieces fit together.
Packages
A Par package is a project directory with a Par.toml file and a src/ directory.
For example:
hello_par/
Par.toml
src/
Main.par
This is exactly what par new hello_par creates.
The Par.toml file starts like this:
[package]
name = "hello_par"
This name is the package’s recommended name. It is used by tooling such as generated
docs.
Dependencies
Packages may depend on other packages through the [dependencies] section:
[package]
name = "postify"
[dependencies]
web = "github.com/author/par-web"
shared = "../shared"
Each dependency has the form:
alias = "reference"
The alias on the left is the name used in imports, such as @web/....
The reference on the right may be one of two things:
- A local path. These are recognized by starting with
.,..,~, or$. - A remote dependency source. Anything else is treated as remote, for example
github.com/faiface/par-cancellable.
Local paths may look like:
shared = "./shared"
common = "../common"
tools = "~/par/tools"
extras = "$PAR_PACKAGES/extras"
Remote dependencies currently have no versioning. Par just fetches the latest contents from the given source.
Managing remote dependencies
Remote dependencies are managed by the CLI:
par addreadsPar.tomland fetches any missing remote dependencies intodependencies/.par updatere-fetches all managed remote dependencies.par add github.com/faiface/par-cancellableboth adds that dependency toPar.tomlunder its recommended name and fetches it.
The dependencies/ directory is managed state. It is not where you write source code.
Transitive remote dependencies are fetched automatically. If the same remote package is reached through multiple dependencies, Par handles that seamlessly and fetches it only once.
Local dependencies are not copied into dependencies/. They stay where they are on disk and are
referenced directly.
Built-in packages
Every package automatically depends on two built-in packages:
@corefor core types and data structures such asString,List,Map,Result, and so on.@basicfor simple I/O such asConsole,Os, andHttp.
These are implicit dependencies, but not implicit imports. Their modules are available to import from, but their names are not automatically in scope inside your source files.
Browsing packages with par doc
The par doc command is all about exploring packages:
- Outside any package,
par docshows the built-in packages. - Inside a package,
par docshows the current package together with its dependencies. par doc --remote github.com/faiface/par-cancellablelets you inspect a remote package without manually adding it as a dependency.
Modules
Modules live under src/, in any directory structure you like.
For example:
src/
Main.par
data/
Post.par
handlers/
api/
Posts.par
Here:
src/Main.pardefines theMainmodule.src/data/Post.pardefines thePostmodule with the pathdata/Post.src/handlers/api/Posts.pardefines thePostsmodule with the pathhandlers/api/Posts.
Notice the split:
- A module has a name such as
Post. - A module also has a path such as
data/Post.
The name is what appears in the file:
module Post
The path is how the module is imported from elsewhere. The file name and the module declaration must match, case-insensitively.
So:
Post.parmust declaremodule Postpost.parmay also declaremodule Posthandlers/api/Posts.parmust declaremodule Posts
The directories contribute to the module’s path, not to its declared module name.
Importing modules
Modules import other modules explicitly.
To import a module from the same package, use its absolute path from src/:
import data/Post
import handlers/api/Posts
Relative module imports are not supported.
Import paths always use forward slashes:
import util/DateTimeUtils
To import a module from a dependency, prefix the path with @alias:
import @web/http/Server
import @shared/FancyModule
Aliasing imports
If two modules would clash, rename them on import:
import @dep1/blah/Data as Data1
import @dep2/bleh/Data as Data2
Grouped imports
Multiple imports can be grouped:
import {
@basic/Console
@core/List
data/Post
}
Grouped imports are just syntax sugar over multiple import statements.
Accessing names from imported modules
Once a module is imported, its exported items are accessed through the module name:
import {
@core/List
@core/String
data/Post
}
dec RenderPosts : String
def RenderPosts = `#{Post.FetchAllFromDB(!)->List.Length} posts`
In general, imported names are accessed as:
Module.Name
Primary types and primary declarations
A module may export a type and/or a declaration with the same name as the module itself.
Those are special: they become available directly under the module name.
For example:
module Post
export {
type Post = box choice {
.title => String,
.content => String,
}
dec Post : [String, String] Post
dec FetchAllFromDB : [!] List<Post>
}
Now another module can write:
import data/Post
and gets access to:
Postas a typePostas a declarationPost.FetchAllFromDBas another exported declaration from the module
This works smoothly with aliases too:
import @core/List as L
After that:
L<a>is the primary type of the moduleL.Map,L.Filter, and so on are other exported declarations
Having both a primary type Post and a primary declaration Post is perfectly fine,
because in Par, types and terms are always distinguishable by syntactic position.
Visibility and exports
There are two related visibility questions:
- Is the module visible outside its package?
- Is a type or declaration visible outside its module?
Exporting a module
Modules are visible inside their own package regardless of export module.
To make a module visible to dependent packages, mark it:
export module List
Exporting items
Types and declarations are module-private by default.
To make them visible outside the module, use export:
export type Iterator<a> = ...
export dec Map : ...
Or grouped:
export {
type Iterator<a> = ...
dec Map : ...
dec Filter : ...
}
There is no export def.
Definitions are always the implementation side. If you want a value to be visible, export its declaration.
The three visibility levels
Putting the two layers together gives three effective visibility modes for items:
export module+ exported item
The item is visible to dependent packages.- Non-exported module + exported item
The item is visible throughout its own package, but not outside it. - Any module + non-exported item
The item is visible only inside its own module.
Visibility is checked through types too
Par also checks that visible API does not mention hidden types.
For example, if a declaration is visible throughout the package, or exported from the package, then its type must not mention a less-visible type. In other words:
- a package-visible item may not mention a module-private type
- a public item may not mention a merely package-visible type
This prevents less-visible helper types from leaking into wider APIs.
Cycles
In the previous section, we already saw that types and definitions may not use one another in a cycle, and package dependencies follow the same spirit: cyclic dependencies between packages are disallowed.
Modules are different, though: cyclic imports between modules of the same package are allowed.
Why is that useful, if definitions still may not form cycles? Because modules often need one another’s types in their signatures, and some definitions in one module may legitimately call definitions in the other as long as no actual usage cycle is formed.
For example, the built-in @core/List module imports @core/Nat because List.Length returns a
Nat. At the same time, @core/Nat imports @core/List because Nat.Range returns a
List<Nat>.
So the modules import each other, but there is still no cyclic usage between the individual definitions themselves.
Multi-file modules
If one file becomes too large, a module may be split across several files in the same directory:
src/
Parser.par
Parser.lexing.par
Parser.errors.par
These all belong to the same module:
module Parser
The rules are:
Parser.parand everyParser.*.parin the same directory are parts of one module.- Every part still declares
module Parser. - All parts share one top-level module namespace.
- Each file has its own imports that apply only within that file.
- All parts must agree on whether the module is marked
export module.
Running a definition
par run is specifically for definitions of type ! — the unit type, comparable to null or an
empty tuple in other languages.
Other non-generic definitions can still be run in the playground, which generates an automatic UI for interacting with them based on their type.
Now that modules have paths, the par run target syntax makes more sense:
- Targets have one of these forms:
path/to/Modulepath/to/Module.Def
- The slash-separated part is always the module path.
- If the target ends right after the module path,
par runlooks for the module’sMaindefinition. - If the target ends with
.Def, Par runs that specific definition from the module.
So:
par runmeansMain.Mainpar run Mainalso meansMain.Mainpar run Main.Othermeans theOtherdefinition in theMainmodulepar run handlers/api/Postsmeanshandlers/api/Posts.Mainpar run handlers/api/Posts.Programmeans theProgramdefinition in thehandlers/api/Postsmodule
Other commands such as par test and par check do not take definition targets like these; they
work on whole packages. What they share with par run is the --package flag, which lets you point
the command at a package path.
That’s the package/module system. With that in place, we can now return to the language itself.
Primitive Types
Before taking a stroll through Par’s types, let’s stop by the values that are not built out of the ordinary type connectives: the primitives.
Par currently has seven primitive types:
Nat– natural numbers, starting from zero, arbitrary size. They are a subtype ofInt.Int– positive and negative whole numbers, arbitrary size.Float– IEEE-754 double-precision floating-point numbers.String– UTF-8 encoded text. It is a subtype ofBytes.Char– a single Unicode character. It is a subtype ofString.Byte– a single 8-bit value. It is a subtype ofBytes.Bytes– a contiguous sequence of bytes.
Primitives are the one place where Par is not fully structural. User-defined types are aliases: their shape is their meaning. Primitive types are opaque, because they need efficient runtime representations and special operations.
Literals
Primitive literals are always available. You do not need to import anything to write them.
def Natural = 42 // Nat
def Integer = -7 // Int
def Floating = 3.14 // Float
def Text = "Hello" // String
def Character = "H" // Char
def OneByte = <<65>> // Byte
def ManyBytes = <<65 66 67>> // Bytes
Integer and natural number literals may use underscores for readability:
def Million = 1_000_000
Float literals have a fractional part, and may use scientific notation:
def Piish = 3.14
def Half = 0.5
def Avogadroish = 6.02e23
Strings use double quotes and normal escape sequences:
def Greeting = "Hello\nWorld"
A Char literal is just a string literal containing exactly one character:
def Letter = "a"
def Newline = "\n"
Byte and bytes literals use double angle brackets. A single byte literal is inferred as Byte;
multiple bytes, or the empty literal, are inferred as Bytes.
def A = <<65>>
def ABC = <<65 66 67>>
def Empty = <<>>
Byte values are stored modulo 256, so out-of-range byte literal values wrap around.
Operators
Numbers are usually manipulated with operators, not with imported helper functions.
def Arithmetic = 1 + 2 * 3 // = 7
def Grouped = {1 + 2} * 3 // = 9
def Ratio = 22.0 / 7.0
def Difference = 10 - 3
def Negative = neg 5
The operators +, *, and / work on Nat, Int, and Float.
The operators - and neg work on signed numbers: Int and Float.
Comparisons work on primitive values too:
def Smaller = 3 < 10 // = .true!
def SameText = "hi" == "hi" // = .true!
def Different = "a" != "b" // = .true!
They produce a Bool, which is described below. Comparisons also chain:
def InRange = 0 <= 5 < 10
Chained comparisons behave as you would expect: the expression above means 0 <= 5 and 5 < 10,
with the middle expression evaluated only once.
Reassigning versions of the arithmetic operators are additionally available in the process syntax, specifically +=, -=, *=, and /=:
def Five = do {
let n = 2
n += 3 // equivalent to `let n = n + 3`
} in n
Booleans
Bool is not a primitive type. It is an ordinary either type from
@core/Bool:
type Bool = either {
.false!,
.true!,
}
Boolean values are written as .true! and .false!.
def Yes = .true!
def No = .false!
Boolean expressions use and, or, and not:
def Both = .true! and .false!
def Either = .true! or .false!
def Neither = not .true!
These same words have extra power in conditions: they short-circuit, and can carry bindings from
matches. That is covered in Conditions & if.
Template Strings
Backtick strings are template strings. They are still String values, but they can contain
interpolation.
Use ${...} to splice in an expression that already has type String:
def Name = "Ada"
def Greeting = `Hello, ${Name}!`
Use #{...} to splice in any value that can be displayed as data:
def Count = 3
def Message = `You have #{Count} messages.`
The #{...} form uses @core/Data.ToString under the hood. It works for primitives and for
ordinary data structures such as pairs, eithers, and lists of data.
Template strings may span multiple lines, and support the usual string escapes. To write syntax that would otherwise start or end template behavior, escape it:
def LiteralPieces = `Use \` for backticks, \${ for string interpolation, and \#{ for data.`
Naming Primitive Types
Literals do not need imports, but explicit type names do.
module Main
import {
@core/Int
@core/String
}
def Age: Int = 42
def Name: String = "Ada"
The same imports give access to helper functions from those modules.
module Main
import {
@core/Int
@core/Nat
}
def Magnitude = Int.Abs(-1000)
def Remainder = Int.Mod(-13, 5)
def Numbers = Nat.Range(0, 5) // *(0, 1, 2, 3, 4)
Every package automatically depends on @core, but its modules are not imported automatically.
Useful Primitive Modules
The primitive modules contain operations that are not just generic arithmetic or comparison.
The examples below are only a taste; use par doc to browse the full built-in API.
@core/Nat
Nat has helpers for finite repetition and natural ranges:
module Main
import @core/Nat
def ThreeSteps = Nat.Repeat(3)
def ZeroToFour = Nat.Range(0, 5)
Nat.Repeat(n) produces a recursive value with exactly n steps. It shows up often when you need
to loop a known number of times.
@core/Int
Int has helpers where the result type is not just “another number”.
module Main
import @core/Int
def Absolute: Nat = Int.Abs(-12)
def Modulo: Nat = Int.Mod(-13, 5)
def FromTo = Int.Range(-2, 3)
@core/Float
Float has constants, conversions, predicates, and math functions:
module Main
import @core/Float
def Tau = 2.0 * Float.Pi
def Root = Float.Sqrt(9.0)
def Rounded = Float.Round(3.6)
def CloseEnough = Float.Equals(1.0, 1.05, 0.1)
Float.Equals remains useful because it compares with a tolerance. The == operator compares data
directly.
@core/String
Strings can be built incrementally:
module Main
import @core/String
def Hello = String.Builder
.add("Hello")
.add(", ")
.add("world!")
.build
They can also be parsed through String.Parser. The parser is a larger tool, useful when you want
to read characters or match patterns:
module Main
import @core/String
def ParserFromText = String.Parser("abc")
@core/Char and @core/Byte
Char.Is and Byte.Is check membership in character or byte classes:
module Main
import {
@core/Byte
@core/Char
}
def Space = Char.Is(" ", .whitespace!)
def HighByte = Byte.Is(<<192>>, .range(<<128>>, <<255>>)!)
@core/Bytes
Bytes has readers, parsers, and builders for byte-oriented protocols:
module Main
import @core/Bytes
def EmptyReader = Bytes.Reader(<<>>)
def Size = Bytes.Length(<<65 66 67>>)
That is enough about primitives for now. The rest of the docs will introduce the structural types that most Par programs are built from.
The let Expression
Just one last stop before setting on a tour through Par’s types and their expressions: the let
expression. It’s for assigning a variable and using it in another expression.
Start with the keyword let, then a lower-case name of the variable, an = sign, a value
to assign to the variable, and finally the keyword in followed by an expression that may use
the variable.
That’s a mouthful.
module Main
import @core/Nat
def Six = let three = 3 in three + three
The left side of the = sign can actually be more than a variable!
For one, it can have an annotation:
def Six = let three: Nat = 3 in three + three
And it can also be a pattern:
def Twelve = let (a, b)! = (3, 4)! in a * b
The above is a combination of a pair and a unit pattern. We’ll learn more about those soon.
Type annotations always go after a variable name. So, this is invalid:
let (a, b)! : (Nat, Nat)! = (3, 4)! in ... // Error!The annotation does not follow a variable. But this is good:
let (a: Nat, b: Nat)! = (3, 4) in ... // Okay.
Now, onto types and their expressions!
Types & Their Expressions
Types in Par serve two seemingly incompatible purposes at the same time:
- Objects of every-day programming, like functions and pairs.
- Session-typed communication channels.
In the world of linear logic, these are the same thing. But to make this connection harmonious and ergonomic, some unusual choices have to be made in the design of the basic building blocks.
Types in Par are sequential. The basic building blocks — pairs, functions, eithers (sums), and choices (co-sums) — all read as first this, then that.
Let’s take pairs. In many programming language, (A, B) is the type of a pair of A and B.
This approach is not sequential: both types assume equal position.
In Par, the pair type is instead (A) B. The second type being outside of the parentheses is
essential. It allows us to sequentially continue the type without the burden of nesting.
Compare (A, (B, (C, D))) against (A) (B) (C) D.
Of course, most languages that provide (A, B) pairs also support triples (A, B, C), and
quadruples (A, B, C, D), so let’s mix it up!
The usual syntax for function types is A -> B. That is sequential, but in Par we have a syntax
that plays more nicely with the pairs: [A] B. Now compare
(A, B -> (C, D -> E))
versus
(A) [B] (C) [D] E
We can read it as: first give A, then take B, then give C, then take D, and finally give E.
This is starting to look a lot like session types! An alternative reading of the type could be:
first send A, then receive B, then send C, then receive D, and finally proceed as E.
And that, in a nutshell, is how Par unifies every-day types with session types.
This chapter covers the every-day aspect of types in Par. For the session-typed, process-oriented aspect, check out The Process Syntax.
Linearity
Par is based on linear logic, and with that comes a linear type system. That means: some values must be used exactly once.
These are called linear values. You can’t copy them, and you can’t throw them away. They must be consumed, exactly once — in a way their type allows.
This might sound limiting, but it opens the door to something powerful.
When a value must be used — and can only be used once — it becomes possible to model communication. Think about a channel that expects you to send a message. If you don’t send one — or send two — things fall apart.
With linearity, Par gives you channels where that simply can’t happen.
That’s the foundation of session types, and Par supports them at its core.
But not every type needs that kind of strictness. Some values should be copyable, droppable, and passed around freely.
So Par distinguishes between:
- Linear types, which must be used exactly once.
- Non-linear types, which can be used any number of times — including zero.
The precise rule is: a type is non-linear when it satisfies the box constraint.
That chapter comes after Box, but here is the useful orientation.
Which types are non-linear?
These include:
- All primitives:
Int,Nat,Float,String,Char,Byte, andBytes - Unit
- Either
- Pair
- Recursive
- Box
- Forall and Exists, when their type parameters and bodies are constrained enough to be non-linear
- Any type composed entirely of non-linear parts
Which types are linear?
All the rest:
- Function
- Choice
- Iterative
- Forall and Exists, when they introduce unconstrained type variables
- Continuation
- Any type that contains a linear component, even deeply
If a type has a linear piece anywhere inside it, it becomes linear — unless that part is wrapped in a box.
Unit
The unit type — spelled ! — has a single value, also !.
def Unit: ! = !
Unit is frequently used as an end-marker for other types. All composite types — such as pairs, eithers, and choices — have an obligatory “and then” part. The unit type does the job for the case of “and then nothing”.
For example, the predefined List<a> type has this definition:
type List<a> = recursive either {
.end!,
.item(a) self,
}
Each variant in an either type has an obligatory payload. For the node marking the
end of the list, the payload is empty, and so it’s !.
Construction
The expression ! has type ! and is the only possible value for this type.
def Unit = ! // infers `Unit` to be of type `!`
Destruction
Being a non-linear type, variables of type ! can be left unused.
If ! is a part of a larger type, it may be needed to assign it as a part of a pattern. For this
purpose, the pattern ! will destruct a ! value without assigning it to a variable.
def TestUnitDestruction = do {
let unit = !
let ! = unit
} in !
This is useful when matching an end of a list:
module Main
import {
@core/Int
@core/List
}
dec GetFirstOrZero : [List<Int>] Int
def GetFirstOrZero = [list] list.case {
.end! => 0, // `!` is a pattern here
.item(x) _ => x,
}
Or when destructing a !-ended tuple:
module Main
import @core/Int
dec SumPair : [(Int, Int)!] Int
def SumPair = [pair]
let (x, y)! = pair // `!` is a pattern here
in x + y
def Five =
let pair = (2, 3)!
in SumPair(pair)
Either
Either types are the well-known sum types, otherwise known as tagged unions.
They defined a finite number of variants, each with a different name and a payload. A value of an either type is one of its variants.
module Main
import {
@core/Int
@core/String
}
type StringOrNumber = either {
.string String,
.number Int,
}
def Str: StringOrNumber = .string "Hello!"
def Num: StringOrNumber = .number 42,
An either type is spelled with the keyword either, followed by curly braces enclosing a
comma-separated list of variants.
Each variant has a lower-case name prefixed by a period and followed by a single, obligatory payload type:
either {
.variant1 Payload1,
.variant2 Payload2,
.variant3 Payload3,
}
Since each payload must be a single type, units, pairs, and other types are used to define composite payloads. For example:
type MaybeBoth<a, b> = either {
.neither!,
.left a,
.right b,
.both(a, b)!,
}
Either types are frequently used together with recursive types to define finite tree-like structures.
type BinaryTree<a> = recursive either { .empty!, .node(a, self, self)!, }The predefined
List<a>type is a combination ofrecursiveandeither:type List<a> = recursive either { .end!, .item(a) self, }
Construction
Values of either types are constructed starting with .name — the name of one of the variants in
the type — followed by an expression of the corresponding payload type.
Here are some examples of constructions for an either type that demonstrates many possible payloads:
type Varied = either {
.unit!, // payload is `!`
.string String, // payload is `String`
.number Int, // payload is `Int`
.pair(Int) String, // payload is `(Int) String`
.symmetricPair(Int, String)!, // payload is `(Int, String)!`
.nested either { // payload is another either type
.left!,
.right!,
},
.nested2(String) either { // payload is a pair of `String` and another either
.left!,
.right!,
}
}
def Example1: Varied = .unit!
def Example2: Varied = .string "Hello!"
def Example3: Varied = .number 42
def Example4: Varied = .pair(42) "Hello!"
def Example5: Varied = .symmetricPair(42, "Hello!")!
def Example6: Varied = .nested.left!
def Example7: Varied = .nested.right!
def Example8: Varied = .nested2("Hello!").left!
def Example9: Varied = .nested2("Hello!").right!
Pairs are frequently used in payloads of either types, both in their symmetric and sequential
styles. The sequential style makes chaining either types with attached payloads very natural, like
in the .nested2 variant.
Destruction
Values of either types can be deconstructed using .case expressions, similar to pattern-matching in
other languages.
A .case expression starts with the value to be destructed, followed by .case, and a list of
comma-separated branches enclosed in curly braces, one per each variant.
value.case {
// branches
}
Each branch consists of the name of its variant, a pattern to assign the payload to, then a =>
followed by an expression computing the result for that branch. All branches must evaluate to the
same type.
// branch
.name pattern => expression,
The patterns to assign the payloads are the same as can appear on the left side of
let assignments:
For a small example, we analyze the Str and Num values of the StringOrNumber type from above:
// evaluates to "Hello!"
def ResultForStr = Str.case {
.string s => s,
.number n => `#{n}`,
}
// evaluates to "42"
def ResultForNum = Num.case {
.string s => s,
.number n => `#{n}`,
}
For a comprehensive example, here’s a big function converting the above Varied type
to a String:
dec VariedToString : [Varied] String
def VariedToString = [varied] varied.case {
.unit! => ".unit!",
.string s => String.Builder.add(".string ").add(String.Quote(s)).build,
.number n => `.number #{n}`,
.pair(n) s =>
`.pair(#{n}) ${String.Quote(s)}`,
.symmetricPair(n, s)! =>
`.symmetricPair(#{n}, ${String.Quote(s)})!`,
.nested inside => String.Builder.add(".nested").add(inside.case {
.left! => ".left!",
.right! => ".right!",
}).build,
.nested2(s) inside =>
String.Builder
.add(".nested2(")
.add(String.Quote(s))
.add(")")
.add(inside.case {
.left! => ".left!",
.right! => ".right!",
}).build,
}
Pair
A pair is two independent values packed into one. The only thing that differentiates pairs in Par, compared to other languages, is their sequential syntax. While unusual, it makes pairs applicable to a much wider set of use-cases.
A pair type consists of two types, the first enclosed in round parentheses.
module Main
import {
@core/Int
@core/String
}
type Pair = (String) Int
If the second type is another pair, we can use syntax sugar to write it more concisely:
type Triple1 = (String) (Int) String
type Triple2 = (String, Int) String
// these two are exactly the same type
For a symmetric pair syntax, it’s idiomatic to use the unit type as the last element.
type SymmetricPair = (String, Int)!
Pairs in their sequential style are frequently used in combination with other types to insert values
into bigger structures. The predefined List<a> type uses a pair for its .item variant:
type List<a> = recursive either {
.end!,
.item(a) self,
}
An infinite stream type may use a pair to produce an element together with the remainder of the stream:
type Stream<a> = iterative choice {
.close => !,
.next => (a) self,
}
Construction
Pair values look the same as their types, with values instead of types in place of elements.
def Example1: Pair = ("Hello!") 42
def Example2: Triple1 = ("Alice") (42) "Bob"
// `Triple1` and `Triple2` really are the same type
def Example3: Triple1 = ("Alice", 42) "Bob"
def Example3: Triple2 = ("Alice", 42) "Bob"
// notice the `!` at the end
def Example4: SymmetricPair = ("Hello!", 42)!
When embedded in other types, sequential pairs blend in seamlessly:
def Names: List<String> = .item("Alice").item("Bob").item("Cyril").end!
// | | |_____________
// | |_________________________
// |_______________________________________
Destruction
Pairs are deconstructed in patterns on assignments. Those can appear in:
let-expressions- function arguments
case/.casebranches
Aside from pairs and whole values, unit types can be matched in patterns, too.
Here are some examples:
def Five: Int =
let (x) y = (3) 2
in x + y
def FiveSymmetrically: Int =
let (x, y)! = (3, 2)!
in x + y
dec AddSymmetricPair : [(Int, Int)!] Int
def AddSymmetricPair = [(x, y)!] x + y
// \_____/<---- pattern here
dec SumList : [List<Int>] Int
def SumList = [list] list.begin.case {
.end! => 0,
.item(x) xs => x + xs.loop,
// \____/<---- pattern here
}
Function
A function transforms an argument into a result. The syntax for function types is designed to work well with the rest of the type system, and resembles the syntax for pairs, because the two are dual to one another.
A function type consists of two types — the argument, and the result — the former enclosed in square brackets.
type Function = [Int] String
If the result is another function, we can use syntax sugar to write it more concisely:
type BinaryFunction1 = [Int] [Int] Int
type BinaryFunction2 = [Int, Int] Int
// these two are exactly the same type
This is the preferred way to define functions of multiple arguments.
Functions are linear. While a globally defined function may be called any number of times, a function stored in a local variable can (and must) only be called once:
module Main
import @core/Int
dec Add : [Int, Int] Int
def Add = [x, y] x + y
// a global function may be called many times
def Six = Add(1, Add(2, 3)) // Okay.
// but a function in a local variable can be only called once
def Illegal =
let inc = Add(1)
in Add(inc(2), inc(3)) // Error!
Linearity brings a lot of expressivity that wouldn’t be possible otherwise. After all, the main purpose of Par is to explore where this new paradigm arising from linear types and duality can take us.
Non-linear functions are achieved using box types.
Construction
Function values bind their argument inside square brackets, followed by an expression computing the result.
dec Double : [Int] Int
def Double = [number] 2 * number
Multi-argument functions — or more precisely: functions returning other functions — can be expressed using the same kind of a syntax sugar as available for their types:
module Main
import @core/String
dec Concat : [String, String] String
// the same as `[String] [String] String`
def Concat = [left, right]
String.Builder.add(left).add(right).build
Patterns for deconstructing pairs and units can be used inside the square brackets:
dec Swap : [(String, Int)!] (Int, String)!
def Swap = [(x, y)!] (y, x)!
Par uses bi-directional type-checking. It’s a style of type-checking that can infer a lot of types, but does not try to guess ahead. Functions are one of the types that it cannot fully infer.
def Identity = [x] x // Error! The type of `x` must be known.
If the type of a function isn’t known ahead of time, at least the type of its argument must be specified explicitly:
def Identity = [x: String] x // Okay.
For generic functions, read up on forall types.
Par has an unusual take on recursion, thanks to its ambitious stride towards totality. Naive recursion by self-reference is not allowed. In other words, a function can’t directly call itself.
def Infinity = 1 + Infinity // Error! Cyclic dependency.Instead, recursive and iterative types are used for recursion and corecursion, respectively. Read up on them to learn more.
Par’s powerful
begin/loopsyntax is a single, universal construct for cyclic computations. It serves well in recursive functions, iterative objects, and imperative-looking loops in process syntax.Forbidding functions from calling themselves may seem limiting at first, but
begin/loopmakes up for it with its perky handling of local variables, and its ability to be used deep in expressions, removing any need for recursive helper functions.
Destruction
Calling a function has the familiar syntax:
def Ten = Double(5) // `Double` defined above
Functions with multiple arguments may be called by comma-separating the arguments inside the parentheses:
def HelloWorld1 = Concat("Hello ", "World") // `Concat` defined above
def HelloWorld2 = Concat("Hello ")("World")
def HelloWorld3 =
let partial = Concat("Hello ")
in partial("World")
All three versions do the same thing.
The word destruction is especially apt here, due to linearity of functions. If a function is stored in a local variable, calling it destroys the variable, as discussed above.
Forall
What about generic functions? Or generic values?
We already know about generic types. For example, here’s a typical optional type, as present in many languages:
type Option<a> = either {
.none!,
.some a,
}
In Par, generic type definitions use the familiar angle bracket syntax. The parameters to those,
such as a for Option<a> may be replaced with anything, such as Option<Int>. The resulting type is,
however, always concrete.
Now consider these two definitions:
module Main
import {
@core/Int
@core/String
}
def None: Option<String> = .none!
dec Swap : [(String, Int)!] (Int, String)!
def Swap = [pair]
let (first, second)! = pair
in (second, first)!
Both are defined in terms of concrete types, but don’t use them: .none! is a valid value for
any Option<a>, and swapping a pair works regardless of its content.
To make these work with anything, we employ forall types!
In Par, forall types:
- Don’t use angle brackets. Instead they are functions taking types.
- Are not inferred. Calling a generic function requires specifying the types.
- Are first-class! It’s possible to store and pass generic values around, without them losing their genericity.
If you want generics inferred at the use site, see Implicit generics.
A forall type consists of two parts:
- A lower-case type variable enclosed in square brackets, and prefixed with the keyword
type. - The result type, which uses this type variable.
dec None : [type a] Option<a>
dec Swap : [type a, type b, (a, b)!] (b, a)!
After erasing the previous concrete definitions for None, these will be their generic types. As we can
see, these look just like functions, but taking types!
If a forall continues into more explicit type binders or value arguments — like with Swap — we keep
them together in one pair of square brackets, repeating type for each explicit type binder:
dec Swap : [type a, type b, (a, b)!] (b, a)!
This keeps the whole input list visible at once.
Explicit type binders can also carry constraints, such as [type a: data]. Those are covered in
Type Constraints.
Just like functions, foralls are linear. Variables containing them can’t be dropped, nor copied, only destructed by calling.
Construction
Values of forall types are constructed the same way as functions, except the argument is a type
variable and prefixed with the keyword type.
Completing the definitions above:
dec None : [type a] Option<a>
def None = [type a] .none!
dec Swap : [type a, type b, (a, b)!] (b, a)!
def Swap = [type a, type b, pair]
let (first, second)! = pair
in (second, first)!
A common complaint at this point is: Why do I have to write
type aandtype bin both the declaration, and the definition? After all, it doesn’t seem like they’re used in the definition. However, they are! What’s the type offirst? It’sa. Andsecond? It’sb. If you called themtype kekandtype dek, they would bekekanddek. Par’s type checker never makes type names up.Additionally, if you do end up needing to use those type variables — for example, to call another generic function — they will be right at hand.
Destruction
Using a forall value looks the same as calling a function, except the argument is a concrete type,
prefixed with the keyword type.
def NoneInt = None(type Int) // type inferred as `Option<Int>`
def Pair = ("Hello!", 42)!
def Swapped = Swap(type String, type Int, Pair)
// = (42, "Hello!")!
Implicit generics
Par already supports explicit generics via forall:
module Main
import {
@core/Int
@core/String
}
dec Swap : [type a, type b, (a, b)!] (b, a)!
def Swap = [type a, type b, pair]
let (first, second)! = pair
in (second, first)!
With forall, callers pass types explicitly when they use Swap:
def Pair = ("Hello!", 42)!
def Swapped = Swap(type String, type Int, Pair)
That is precise and fully explicit. But in many everyday cases, the types are obvious from the value you are passing. For those cases, Par also has implicit generics.
Syntax
Implicit generics are not a standalone type. The <a, ...> binder is an
extension of a function type: it must appear immediately
before the [...] of that type.
<a, b>[Arg] Res
You cannot write <a> in front of either, choice, box, or anything else.
The key rule is local inference:
Implicit type variables are inferred only from the single argument
immediately following the <...> binder.
This is also reflected in the syntax: the bracket right after <...> must
contain exactly one argument type. If you need multiple value arguments, you
still write a curried function type.
So this is valid:
dec Concat : <a>[List<a>] [List<a>] List<a>
But this is not valid syntax:
dec Concat : <a>[List<a>, List<a>] List<a>
When calling such a function, you can still pass all arguments at once:
Concat(left, right)
The type is still written in curried form, because inference must happen from that first argument alone.
One more important point: there is no syntax for “manually specifying” implicit type arguments. When designing an API you choose, for each type variable, whether it is implicit or explicit:
- If it is implicit (
<a>), it is always inferred. - If it is explicit (
[type a]), it is always specified by the caller.
This is intentional: it keeps call sites predictable.
Implicit type parameters can also carry constraints, such as <a: box> or
<a: data>. The constraints themselves are covered in Type Constraints.
Construction
Start with the Swap example, but make it implicit:
dec Swap : <a, b>[(a, b)!] (b, a)!
To construct a value of this type, you also introduce the implicit type names at the term level, and then receive the value argument:
dec Swap : <a, b>[(a, b)!] (b, a)!
def Swap = <a, b>[pair]
let (first, second)! = pair
in (second, first)!
This is intentionally different from forall: an implicit generic and an
explicit forall generic are different types, and they do not subtype into one
another.
You can also use implicit generics when the type variable is nested inside a larger argument:
dec Flatten : <a>[List<List<a>>] List<a>
Destruction
To use an implicit generic, you call it like an ordinary function:
def Swapped = Swap(Pair)
Here a = String and b = Int are inferred from the type of Pair (the
argument immediately following <a, b>).
If you want to steer inference, you can still add annotations locally, for example by ascribing a type to an expression:
type T in expr
For example (this is a bit contrived, but it shows the point):
Concat(type List<Nat> in *(), numbers)
If you wrote Concat(*(), numbers), the empty list *() would lead a to be
inferred as either {} (an impossible type), so inference would not pick Nat
for you.
When implicit generics are a bad fit
Implicit generics infer their type variables from the argument value. This works great when that argument already has a clear type (globals, variables, fully typed expressions), but it becomes harder when the argument’s type cannot be inferred without annotations.
A classic example is an anonymous function. The box here is not the point —
it just happens that Map takes a boxed function.
Map(numbers, box [x: Int] `#{x}`) // fine: `x` has a known type
Map(numbers, box [x] `#{x}`) // may fail without more info
(Map is discussed in Box.)
In the second call, the type of [x] ... cannot be inferred unless the type of
x is specified. If the function’s type parameters are being inferred from the
mapper argument itself, you end up in a chicken-and-egg situation.
The usual fix is to add an annotation:
Map(numbers, box [x: Int] `#{x}`)
This is why implicit generics can be made difficult by higher-order arguments like lambdas: if the type of the lambda argument is not already specified, the lambda’s type won’t be inferred.
For example, if Map tried to infer the result type from the mapper itself:
dec Map : <a>[List<a>] <b>[box [a] b] List<b>
then a call like this may fail:
Map(numbers, box [x] `#{x}`)
because the type of x is not specified, so the type of the function cannot be
inferred, so b cannot be inferred either. You end up needing to annotate x:
Map(numbers, box [x: Int] `#{x}`)
Many “map-like” APIs therefore prefer to infer the input type and keep the output type explicit, e.g.:
dec Map : <a>[List<a>] [type b, box [a] b] List<b>
With this type, the mapper is checked against the expected type box [a] b, so
x can be inferred as a and usually needs no annotation. Picking the result
type b is also often more natural than restating the argument type.
Implicit generics and pairs
Implicit generics also exist for pair types. This is the implicit
counterpart of exists.
Just like with functions, the <a, ...> binder is part of the following pair
type: it must appear right before the (...) of that pair type.
Here is a simple example. AnyDrop stores a value of some unknown type, plus a
small “vtable” for dropping it (a boxed choice):
type AnyDrop = <a>(a) box choice {
.drop(a) => !,
}
This is the implicit counterpart of the existential type:
type DropMe = (type a, a) box choice {
.drop(a) => !,
}
Construction
Notice that you do not specify the hidden type when constructing an AnyDrop:
def Example: AnyDrop = (7) box case {
.drop(_) => !,
}
Destruction
Dually, when you unpack an implicit-generic pair, you introduce a local type variable:
let <a>(value) vtable = Example
vtable.drop(value)
This is the “mirror image” of implicit-generic functions: there you introduce
<a, ...> at construction time and inference happens at call time; here you
construct without naming a, and introduce a when unpacking.
Recursive
Par has, among others, these two ambitious design choices:
- Totality, meaning preventing infinite loops by type-checking.
- A structural type system, where global type definitions are merely aliases.
When it comes to self-referential types, totality necessitates distinguishing between:
- Recursive types, those are finite.
- Corecursive types, potentially infinite. In Par, we call them iterative types.
The choice of a structural type system has led to avoiding defining self-referential types naively, and instead adding a first-class syntax for anonymous self-referential types.
Par is very radical here. If you try the usual way of defining a singly-linked list, it fails:
type IllegalList = either {
.end!,
.item(String) IllegalList, // Error! Cyclic dependency.
}
In general, cyclic dependencies between global definitions are disallowed. Instead, we have:
- Anonymous self-referential types:
recursiveanditerative. - A single, universal recursion construct:
begin/loop. It’s suitable for recursive destruction, iterative construction, and imperative-style loops in process syntax.
Let’s take a look at recursive!
Totality does not mean you can’t have a web server, or a game. While these are often implemented using infinite event loops, it doesn’t have to be done that way. Instead, we can employ corecursion, which Par supports with its iterative types.
To make it clearer, consider this Python program:
def __main__(): while True: req = next_request() if req is None: break handle_request(req)That’s a simplified web server, handling requests one by one, using an infinite loop.
Could we switch it around and not have an infinite loop? Absolutely!
class WebServer: def close(self): pass def handle(req): handle_request(req) def __main__(): start_server(WebServer())A small restructuring goes a long way here. Iterative types in Par enable precisely this pattern, but with the ergonomics of the infinite loop version.
A recursive type starts with the keyword recursive followed by a body that may contain any number
of occurrences of self: the self-reference.
type LegalList = recursive either {
.end!,
.item(String) self, // Okay.
}
If there are nested
recursive(oriterative) types, it may be necessary to distinguish between them. For that, we can attach labels torecursiveandself. That’s done with an@:recursive@label,self@label. Any lower-case identifier can be used for the label.
The recursive type can be thought of as being equivalent to its expansion. That is, replacing each
self inside the body with the recursive type itself:
- The original definition:
recursive either { .end!, .item(String) self } - The first expansion:
either { .end!, .item(String) recursive either { .end!, .item(String) self } } - The second expansion:
either { .end!, .item(String) either { .end!, .item(String) recursive either { .end!, .item(String) self } } } - And so on…
The body of a
recursiveoften starts with aneither, but doesn’t have to. Here’s an example of that: a non-empty list, which starts with a pair.type NonEmptyList<a> = recursive (a) either { .end!, .item self, }Another example of a
recursivetype, which doesn’t start with aneitherwould be a finite stream.type FiniteStream<a> = recursive choice { .close => !, .next => either { .end!, .item(a) self, } }This one starts with a choice, which enables polling the elements on demand, or cancelling the rest of the stream. However, being recursive, a
FiniteStream<a>is guaranteed to reach the.end!eventually, if not cancelled.There is nonetheless an important restriction: in order for
selfreferences to remain useful, everyselfreference for arecursivemust be guarded by aneither. Theeitherdoesn’t have to be right next to therecursive, but it has to be somewhere in-betweenrecursiveandself:type ValidList<a> = recursive (a) either { .end!, .item self, // Okay. This `self` is guarded by an `either`. } type InvalidList<a> = recursive (a) self // Error! Unguarded `self` referenceIterative types have a similar restriction: their
selfreference must be guarded by achoice.
The key features of recursive types are that their values are finite, and that we can perform recursion on them.
Construction
Recursive types don’t have any special construction syntax. Instead, we directly construct their bodies, as if they were expanded.
type Tree = recursive either {
.leaf Int,
.node(self, self)!,
}
def SmallTree: Tree = .node(
.node(
.leaf 1,
.leaf 2,
)!,
.node(
.leaf 3,
.leaf 4,
)!,
)!
Already constructed recursive values can be used in the self-places of new ones:
def BiggerTree: Tree = .node(SmallTree, SmallTree)!
Lists are a frequently used recursive type, and so are predefined as:
type List<a> = recursive either {
.end!,
.item(a) self,
}
Constructing them goes like:
dec OneThroughFive : List<Int>
dec ZeroThroughFive : List<Int>
def OneThroughFive = .item(1).item(2).item(3).item(4).item(5).end!
def ZeroThroughFive = .item(0) OneThroughFive
Because lists are so ubiquitous, there is additionally a syntax sugar for constructing them more concisely:
def OneThroughFive = *(1, 2, 3, 4, 5)
However, prepending onto an existing list has no syntax sugar, so ZeroThroughFive still has to be
done the same way.
Destruction
If we don’t need to perform recursion, it’s possible to treat recursive types as their expansions
when destructing them, too. For example, here we treat a List<String> as its underlying either:
type Option<a> = either {
.none!,
.some a,
}
dec Head : [List<String>] Option<String>
def Head = [list] list.case {
.end! => .none!,
.item(x) _ => .some x,
}
For a recursive reduction, we have .begin/.loop. Here’s how it works:
- Apply
.beginto a value of arecursivetype. - Apply more operations to the resulting expanded value.
- Use
.loopon a descendent recursive value, descendent meaning it was aselfin the original value we applied.beginto.
Let’s see it in practice. Suppose we want to add up a list of integers.
- We obtain a value (
list) of a recursive type (List<Int>):dec SumList : [List<Int>] Int def SumList = [list] - We apply
.beginto it:list.begin - We match on the possible variants:
If the list is empty, the result is.case { .end! => 0, .item(x) xs =>0. Otherwise, we need to add the numberx
to the sum of the rest of the list:x +xs. - Since
xsis a descendant of the originallistthat we applied the.beginto, and is again aList<Int>, we can recursively obtain its sum using.loop:
And close the braces.xs.loop}
All put together, it looks like this:
def SumList = [list] list.begin.case {
.end! => 0,
.item(x) xs => x + xs.loop,
}
You can think of .loop as going back to the corresponding .begin, but with the new value.
The semantics of .begin/.loop are best explained by expansion, just like the recursive types
themselves. In all cases, the meaning of .begin/.loop is unchanged, if we replace each .loop with the entire body starting at .begin.
Observe:
- The original code:
def SumList = [list] list.begin.case { .end! => 0, .item(x) xs => x + xs.loop, } - The first expansion:
def SumList = [list] list.case { .end! => 0, .item(x) xs => x + xs.begin.case { .end! => 0, .item(x) xs => x + xs.loop, }, } - The second expansion:
def SumList = [list] list.case { .end! => 0, .item(x) xs => x + xs.case { .end! => 0, .item(x) xs => x + xs.begin.case { .end! => 0, .item(x) xs => x + xs.loop, }, }, } - And so on…
.loop may be applied to any number of descendants. Here’s a function adding up the leafs in the Tree
type defined previously:
dec SumTree : [Tree] Int
def SumTree = [tree] tree.begin.case {
.leaf number => number,
.node(left, right)! => left.loop + right.loop,
}
def BiggerSum = SumTree(BiggerTree) // = 20
If there are multiple nested
.begin/.loop, it may be necessary to distinguish between them. Labels can be used here too, just like with the types:.begin@labeland.loop@labeldoes the job.TODO:
type Tree<a> = recursive List<(a) self>
Retention of local variables
Let’s consider Haskell for a moment. Say we write a simple function that increments each item in a list by a specified amount:
incBy n [] = []
incBy n (x:xs) = (x + n) : incBy n xs
This recursive function has a parameter that has to be remembered across the iterations: n, the
increment. In Haskell, that’s achieved by explicitly passing it to the recursive call.
Now, let’s look at Par. In Par, .loop has a neat feature:
local variables are automatically passed to the next iteration.
dec IncBy : [List<Int>, Int] List<Int>
def IncBy = [list, n] list.begin.case {
.end! => .end!,
.item(x) xs => .item(x + n) xs.loop,
}
Notice, that xs.loop makes no mention of n, the increment. Yet, n is available throughout the
recursion, because it is automatically passed around.
This feature is what makes begin/loop not just a universal recursion construct, but a sweet spot
between usual recursion and imperative loops.
If you’re confused about how or why it should work this way, try expanding the
.begin/.loopin the above function. Notice that when expanded,nis in fact visible in the next iteration. It’s truly the case that expanding a.begin/.loopnever changes its meaning.
Together with .begin/.loop being usable deep in expressions, local variable retention is also
very useful in avoiding the need for helper functions.
Let’s again switch to Haskell, and take a look at this list reversing function:
reverse list = reverseHelper [] list
reverseHelper acc [] = acc
reverseHelper acc (x:xs) = reverseHelper (x:acc) xs
This function uses a state: acc, the accumulator. It prepends a new item to it in every iteration,
eventually reversing the whole list. In Haskell, this requires a helper recursive function.
In Par, it doesn’t!
dec Reverse : [type a, List<Int>] List<Int>
def Reverse = [type a, list]
let acc: List<a> = .end!
in list.begin.case {
.end! => acc,
.item(x) xs => let acc = .item(x) acc in xs.loop,
}
def TestReverse = Reverse(type Int, *(1, 2, 3, 4, 5)) // = *(5, 4, 3, 2, 1)
And there we go! All we had to do was to re-assign acc with the new value, and continue with xs.loop.
The escape-hatch from totality: .unfounded
If the Par’s type checker refuses to accept your recursive algorithm despite you being certain it’s
total — meaning it resolves on all inputs — it’s possible to disable the totality checking by
replacing .begin with .unfounded.
Par’s totality checking is currently not powerful enough for some algorithms, especially divide
and conquer, and it’s also lacking when decomposing recursive algorithms into multiple functions.
In such cases, using .unfounded is okay. We do, however, aim to make the type system stronger,
and eventually remove .unfounded.
Choice
The famous slogan of sum types is: Make illegal states unrepresentable!
Choice types — the dual of sum types, also known as codata — deserve an equally potent slogan:
Make illegal operations unperformable!
Choice types are somewhat related to interfaces, like in Go, or Java, but I encourage you to approach them with a fresh mind. The differences are important enough to consider choice types their own thing.
A choice type is defined by a finite number of branches, each with a different name and a result.
Values of a choice type are objects that can (and must) be destructed using one of the available branches, to obtain its result.
type ChooseStringOrNumber = choice {
.string => String,
.number => Int,
}
A choice type is spelled with the keyword choice, followed by curly braces enclosing a
comma-separated list of branches.
Each branch has a lower-case name prefixed by a period, followed by =>, and a single obligatory
result type.
choice {
.branch1 => Result1,
.branch2 => Result2,
.branch3 => Result3,
}
If the result is a function, we can use syntax sugar, and move the argument to the left side of the arrow, inside round parentheses:
type CancellableFunction<a, b> = choice {
.cancel => !,
//.apply => [a] b,
.apply(a) => b,
}
Like functions, choice types are linear. A value of a choice type may not be dropped, or copied. It must be destructed exactly once, using one of its branches.
Choice types are frequently used together with iterative types to define objects that can be acted upon repeatedly. For example, the built-in
Consoletype from@basic/Consoleobtained as a handle to print to the standard output is an iterative choice:type Console = iterative choice { .close => !, .print(String) => self, }Then it can be used to print multiple lines in order:
module Main import @basic/Console def Main = Console.Open .print("First line.") .print("Second line.") .print("Third line.") .close
Construction
Values of choice types are constructed using standalone case expressions.
def Example: ChooseStringOrNumber = case {
.string => "Hello!",
.number => 42,
}
Each branch inside the curly braces follows the same syntax as the branches in the corresponding type, except with types replaced by their values.
def FormatInt: CancellableFunction<Int, String> = case {
.cancel => !,
.apply(n) => `#{n}`,
}
Unlike patterns in .case branches of either types, branches in case
expressions of choice types don’t have a payload to bind: they produce a result. However, we can
still bind function arguments on the left side of the arrow.
Destruction
Choices are destructed by selecting a branch, transforming it into the corresponding result.
We do it by applying .branch after a value of a choice type.
def Number = Example.number // = 42
Above, we defined the type CancellableFunction<a, b>, and a value of that type: FormatInt.
Bare functions are linear, so we must call them, but the cancellable function
gives us a choice of either calling it, or not.
We can use this to define a map function for optional values:
type Option<a> = either {
.none!,
.some a,
}
dec MapOption :
[type a, type b, Option<a>, CancellableFunction<a, b>]
Option<b>
def MapOption = [type a, type b, option, func] option.case {
.none! => let ! = func.cancel in .none!,
// \_________/
.some x => let y = func.apply(x) in .some y,
// \________/
}
def Result = MapOption(type Int, type String, .some 42, FormatInt) // = .some "42"
This example also shows that in Par, you don’t have to be shy about writing your types on multiple lines. The syntax is designed for that.
Iterative
We already covered one kind of self-referential types: recursive types. Now we cover the other kind: iterative types. They are also known as coinductive, or corecursive types, because they enable corecursion.
In a nutshell:
- Values of recursive types are something repeated some number of times.
- Values of iterative types can repeat something any number of times.
Recursive types tell you how many times you need to step through them to reach the end. That’s what
.begin/.loop does. If there is a self, you can always .loop through it, and proceed with the
recursion until you reach the end.
But iterative types let you tell them how many times you want to repeat them. They have the ability to unfold as many times as you like. It’s up to you, the consumer, to proceed.
So, let’s take a look at the iterative types.
An iterative type starts with the keyword iterative followed by a body that may contain any number
of occurrences of self. Notice that the pattern is the same as with recursive types.
The prototypical iterative type — and a good example to study — is an infinite sequence.
type Sequence<a> = iterative choice {
.close => !,
.next => (a) self,
}
If there are nested
iterative(orrecursive) types, it may be necessary to distinguish between them. For that, we can attach labels toiterativeandself. That’s done with an@:iterative@label,self@label. Any lower-case identifier can be used for the label.
Iterative types are always linear, regardless of what’s in their bodies. As such, they can’t be dropped, nor copied.
Notice that we included a .close branch on the inner choice. Since Sequence<a> is
a linear type, there would be no way to get rid of it if it only contained the .next branch.
Just like recursive types, iterative types can be equated with their expansions:
- The original definition:
type Sequence<a> = iterative choice { .close => !, .next => (a) self, } - The first expansion:
type Sequence<a> = choice { .close => !, .next => (a) iterative choice { .close => !, .next => (a) self, }, } - The second expansion:
type Sequence<a> = choice { .close => !, .next => (a) choice { .close => !, .next => (a) iterative choice { .close => !, .next => (a) self, }, }, } - And so on…
Just like
recursivetypes,iterativetypes have an important restriction: everyselfreference for aniterativemust be guarded by achoice. Thechoicedoesn’t have to be right next to theiterative, but it has to be somewhere in-betweeniterativeandself:type ValidSequence<a> = iterative (a) choice { .close => !, .next => self, // Okay. This `self` is guarded by a `choice`. } type InvalidSequence<a> = iterative (a) self // Error! Unguarded `self` reference
So, if both recursive and iterative types can be equated with their expansions, what’s the difference? The difference lies in their construction and destruction:
- Recursive types are constructed step by step and destructed by loops.
- But, iterative types are constructed by loops and destructed step by step.
Let’s see what that means!
Construction
Values of iterative types are constructed using standalone begin/loop expressions. They start with
begin, followed by an expression of the body type. Inside this expression, use a standalone loop
in the self places of the body type to go back to the corresponding begin.
Just like with recursive’s
.begin/.loop, it’s possible to use labels to distinguish between nestedbegin/loop(and.begin/.loop) uses. Just use@:begin@labelandloop@label.
Here’s a simple Sequence<Int> that produces the number 7 forever:
module Main
import @core/Int
dec SevenForever : Sequence<Int>
def SevenForever = begin case {
.close => !,
.next => (7) loop,
}
The .next branch produces a pair, as per the sequence’s body type, with the second element being
the new version of the sequence. Here we use loop to accomplish that corecursively, looping back
to the begin.
The corecursive meaning of begin/loop can again be understood by seeing its expansions:
- The original code:
def SevenForever = begin case { .close => !, .next => (7) loop, } - The first expansion:
def SevenForever = case { .close => !, .next => (7) begin case { .close => !, .next => (7) loop, }, } - The second expansion:
def SevenForever = case { .close => !, .next => (7) case { .close => !, .next => (7) begin case { .close => !, .next => (7) loop, }, }, } - And so on…
Retention of local variables works the same as in recursive’s .begin/.loop.
With iterative types, we can use it to carry and update the internal state of the iterative object.
For example, here’s an infinite sequence of fibonacci numbers:
module Main
import @core/Nat
def Fibonacci: Sequence<Nat> =
let (a, b)! = (0, 1)!
in begin case {
.close => !,
.next =>
let (a, b)! = (b, a + b)!
in (a) loop
}
This is very useful. In most programming languages, constructing a similar Fibonacci object would
require defining a class or a struct describing the internal state, and then updating it in
methods. In Par, iterative objects can be constructed using anonymous expressions, with no need
of specifying their internal state by a standalone type: the internal state is just local variables.
In the Fibonacci’s case, the internal state is non-linear. That’s why we’re able to return a bare unit
in the .close branch: a and b get dropped automatically.
Let’s take a look at a case where the internal state is linear! Suppose we need a function that takes
an arbitrary sequence of integers, and increments its items by 1, producing a new sequence.
dec Increment : [Sequence<Int>] Sequence<Int>
def Increment = [seq] begin case {
.close => let ! = seq.close in !,
.next =>
let (x) seq = seq.next
in let x = x + 1
in (x) loop
}
def FibonacciPlusOne = Increment(Fibonacci)
In this case, we need to explicitly close the input seq in the .close branch. It’s linear, so
we can’t just drop it.
The escape-hatch from totality: unfounded
Just like with recursive destruction,
it may happen that your iterative construction is total — meaning it never enters an infinite,
unproductive loop — yet not accepted by Par’s type checker. In such cases, it’s possible to
disable Par’s totality checking by replacing begin with unfounded.
Destruction
Iterative types don’t have any special syntax for destruction. Instead, we just operate on their bodies directly, as if they were expanded.
For example, here’s a function to take the first element from a sequence and close it:
def Head = [type a, seq: Sequence<a>]
let (x) seq = seq.next
in let ! = seq.close
in x
Using recursion, we can destruct an iterative type many times. Here’s a function to take the first N elements of a sequence and return them in a list:
dec Take : [type a, Nat, Sequence<a>] List<a>
def Take = [type a, n, seq] Nat.Repeat(n).begin.case {
.end! => let ! = seq.close in .end!,
.step remaining =>
let (x) seq = seq.next
in .item(x) remaining.loop
}
Box
Par has a linear type system. By default, values must be used exactly once.
But not all values need that kind of discipline. Sometimes, you want to:
- Pass a function around multiple times.
- Discard an unused value.
- Compose higher-order utilities freely.
That’s where box types come in.
Non-linear types — even without box
Even without box types, some types in Par are already non-linear. These are the data types:
- Unit
- Either
- Pair
- Recursive
- All the primitives:
Int,Nat,Float,String,Char,Byte,Bytes.
Any combination of these is always non-linear — they can be copied and discarded freely.
But types that contain functions, choices, and other non-data types are linear — no matter how deeply nested.
Now, consider this: what if you want to apply a function to each element in a list?
A plain function in Par is linear — it can only be used once. So applying it repeatedly requires a workaround.
Reusable functions, the hard way
Without box, we can build reusable functions by encoding a usage protocol manually:
type Mapper<a, b> = iterative choice {
.close => !,
.apply(a) => (b) self,
}
This protocol gives us:
.applyto use the function..closeto clean up.
Here’s a Map function that uses it:
dec Map : [type a, type b, List<a>, Mapper<a, b>] List<b>
def Map = [type a, type b, list, mapper] list.begin.case {
.end! => let ! = mapper.close in .end!,
.item(x) xs => let (x1) mapper = mapper.apply(x) in .item(x1) xs.loop,
}
And using it:
def NumberStrings = Map(type Int, type String, Int.Range(1, 100), begin case {
.close => !,
.apply(n) => (`#{n}`) loop,
})
This works — but it’s verbose.
Every reusable function needs to be manually encoded with a protocol like Mapper.
Copying, closing, and chaining all become manual work.
Box types to the rescue
Instead of encoding reusability into the type manually, Par lets you box a value.
A box T is a non-linear version of any type T. You can:
- Copy a
box T. - Drop a
box T. - Pass it around freely.
You can construct boxed values using:
box <expression>
This constructs a value of type box T, where T is the type of the expression.
The only rule is: You can only capture non-linear variables in a box expression.
That includes:
- Data types (
Int,String,List<Int>, etc.) - Other
boxvalues.
The word capture here refers to using local variables inside the expression that were created outside of that expression.
A better Map
With box, we can rewrite the Map function much more cleanly:
module Main
import @core/List
dec Map : <a>[List<a>] [type b, box [a] b] List<b>
def Map = <a>[list] [type b, f] list.begin.case {
.end! => .end!,
.item(x) xs => .item(f(x)) xs.loop,
}
Let’s try it out:
def NumberStrings = Map(Int.Range(1, 100), type String, box [n] `#{n}`)
No wrappers, no manual protocols. The boxed function can be used freely, because the box type makes
it non-linear. This is exactly what box was made for.
Subtyping
Boxed types fit naturally into Par’s subtyping.
A box T can be used anywhere a T is expected.
def BoxInt: box Int = 42 // OK: Int is non-linear
def UseInt: Int = BoxInt // OK: box Int can be used as Int
And if T is already non-linear, then T can be used anywhere a box T is expected.
def Boxes: List<box Int> = *(1, 2, 3)
def Ints: List<Int> = Boxes
For non-linear types, T and box T are effectively interchangeable.
Another example: Filtering a list
Let’s write a function that filters a list using a boxed predicate.
This example uses a box type constraint, written a: box. The next chapter covers constraints
properly; for now, read it as saying: “the element type must be non-linear, because rejected
elements are discarded.”
module Main
import {
@core/Bool
@core/Int
@core/List
}
dec Filter : <a: box>[List<a>] [box [a] Bool] List<a>
def Filter = <a: box>[list] [predicate] list.begin.case {
.end! => .end!,
.item(x) xs => predicate(x).case {
.true! => .item(x) xs.loop,
.false! => xs.loop,
}
}
Note the types:
- We accept a
List<a>. - The constraint
a: boxsays elements may be discarded. - The result is still a
List<a>.
Let’s try it out:
def Evens = Filter(Int.Range(1, 100), box [n] {Int.Mod(n, 2) == 0})
Here:
Int.Range(1, 100)gives aList<Int>.Intsatisfies theboxconstraint, because integers are non-linear.- The result is inferred as
List<Int>.
This keeps the list type clear. The constraint says what the implementation needs, without
wrapping every element in a redundant box.
Type Constraints
Generic code often needs to know a little bit about an unknown type.
For example, this function can return its argument without knowing anything about a:
dec Identity : <a>[a] a
def Identity = <a>[x] x
But this one needs to use its value twice:
dec Duplicate : <a: box>[a] (a, a)!
def Duplicate = <a: box>[x] (x, x)!
The : box part is a type constraint. It says that the unknown type a must be non-linear,
so values of that type may be reused or dropped.
Par currently has four constraints:
boxdatanumbersigned
They form a chain from broadest to narrowest:
signed -> number -> data -> box
So every signed type is also a number, every number is also data, and every data type is
also box.
Syntax
Constraints are written after type parameters with a colon.
Explicit generic functions use type binders:
dec ZeroOr : [type a: number, Bool, a] a
Implicit generic functions use angle-bracket binders:
dec Sum : <a: number>[(a) a] a
Existential types can constrain the hidden type:
type SomeData = (type a: data) a
Implicit generic pairs can do the same:
type DataWithText = <a: data>(a) String
When you construct a value with a constrained explicit binder, the checked type must satisfy the same constraint:
dec ShowTwice : [type a: data, a] String
def ShowTwice = [type a: data, x] `#{x} #{x}`
Named type definitions are the one place where parameters are not constrained:
type Boxed<a> = box a // OK
type Bad<a: box> = box a // Error
If a type definition needs constrained behavior, put the constraint on the functions that operate on that type.
The box Constraint
The box constraint means values are non-linear. A value whose type is known only as a: box may
be copied, reused, or dropped.
dec KeepFirst : <a: box>[(a, a)!] a
def KeepFirst = <a: box>[(first, second)!] first
In the example, second is not used. That is allowed because a: box.
Types that satisfy box include:
- primitives
!- pairs, eithers, and recursive types whose parts also satisfy
box - explicit
box T - type aliases that expand to a
boxtype - type variables with a
box,data,number, orsignedconstraint
Functions, choices, continuations, and unrestricted type variables do not satisfy box unless they
are wrapped in an explicit box.
The data Constraint
The data constraint means values are ordinary data. Data values are non-linear, and additionally
support:
- comparison operators:
<,>,<=,>=,==,!= - data interpolation in template strings:
#{...}
dec Min : <a: data>[(a) a] a
def Min = <a: data>[(left) right] if {
left <= right => left,
else => right,
}
dec Label : <a: data>[a] String
def Label = <a: data>[value] `value = #{value}`
The comparison operators use @core/Data.Compare under the hood. The #{...} template form uses
@core/Data.ToString.
Types that satisfy data include:
- all primitive types
!- pairs whose elements are data
- eithers whose payloads are data
- recursive types whose bodies are data
- type aliases that expand to data
- type variables with a
data,number, orsignedconstraint
Adding box to a non-data type does not make it data:
box [Int] Int // box, but not data
If T is already data, then box T can still be used as data, because boxed data can be used as
the data value inside.
The number Constraint
The number constraint is for generic numeric code. A number type supports:
+*/Number.Zero(type a)
module Main
import @core/Number
dec SumPair : <a: number>[(a) a] a
def SumPair = <a: number>[(left) right] left + right
dec Zero : [type a: number] a
def Zero = [type a: number] Number.Zero(type a)
The number types are:
NatIntFloat
Type aliases that expand to one of these types, and type variables constrained with number or
signed, also satisfy number.
number does not provide subtraction or negation, because Nat is a number but not signed.
The signed Constraint
The signed constraint is the numeric constraint for types that support negative values. It has
everything from number, plus:
-neg
dec Difference : <a: signed>[(a) a] a
def Difference = <a: signed>[(left) right] left - right
dec Negate : <a: signed>[a] a
def Negate = <a: signed>[value] neg value
The signed types are:
IntFloat
Type aliases that expand to Int or Float, and type variables constrained with signed, also
satisfy signed.
Nat is intentionally not signed.
Choosing a Constraint
Use the weakest constraint that gives the function what it needs:
- Use
boxwhen you only need to copy, reuse, or drop values. - Use
datawhen you need comparison or#{...}display. - Use
numberwhen you need generic zero, addition, multiplication, or division. - Use
signedwhen you also need subtraction or negation.
This keeps generic APIs as flexible as possible while still making their capabilities clear.
Exists
An exists type lets a value hide a type inside itself — while exposing only what can be done with that type.
They’re the dual of the parametric types: forall. A forall type [type a] ... says:
“You can give me any type a, and I’ll work with it.” On the other hand, an exists type (type a) ...
says: “I have chosen some specific type a, but I’m not going to tell you what it is.”
An exists type consists of two parts:
- A lowercase type variable enclosed in round parentheses, prefixed with the keyword
type. - The payload type — a type that may use the hidden type variable.
It’s similar to a pair, but the first component is a type instead of a value.
The hidden type can also carry a constraint, such as (type a: data), as covered in
Type Constraints.
Here are two simple examples of existential types:
type Any = (type a) a
type DropMe = (type a, a) choice {
.drop(a) => !,
}
The first one is completely opaque — a value of Any gives you a value of the hidden type, but no
operations to perform on it. That makes it useless, but it’s the simplest example of an exists type.
The second one offers just one operation: dropping a value of that type. It gives us a pair: a value of the hidden type, plus a choice with just one operation: dropping a value of that type.
Let’s now see how existential types are used.
Construction
To construct an existential value, you must pick a concrete type and provide a matching payload.
The syntax is the same as for pairs, with the addition of the type keyword.
Here’s a value of type Any:
def Hidden: Any = (type Int) 42
But since the type is hidden inside Any, with no operations provided, this value is completely useless —
we can’t do anything with it. In fact, we can’t even get rid of it, if we were to instantiate it into a
variable.
Let’s now look at a slightly more interesting example:
type DropMe = (type a, a) choice {
.drop(a) => !,
}
The payload here is a pair: a value of the hidden type, plus a choice with just one operation: dropping a value of that type.
Here’s how we can construct a value of DropMe:
def Drop42: DropMe = (type Int, 42) case {
.drop(n) => !, // `n`, being an `Int`, is dropped by being unused
}
Destruction
To use an existential value, you must unpack it. The syntax is the same as unpacking a pair, just with the type keyword.
Here’s an example that unpacks and uses a DropMe:
def UseDrop: ! =
let (type a, x) dropper = Drop42
in dropper.drop(x)
The pattern (type a, x) dropper means:
abecomes the name of the hidden type, a local type variable.xis the stored value of typea.dropperis the choice with the.dropmethod.
We can also unpack existentials in function parameters, using patterns. Here’s a function that takes
a DropMe and drops its inner value:
dec DropIt : [DropMe] !
def DropIt = [(type a, x) dropper] dropper.drop(x)
A Real Example
Exists types become truly useful when combined with box types — allowing you to hide implementation details inside interfaces that can be passed around freely.
Here’s a boxed interface for working with sets:
type SetModule<a> = (type set: box) box choice {
.empty => set,
.insert(a, set) => set,
.contains(a, set) => Bool,
}
This type hides the implementation type of the set.
The interface is boxed, so it can be copied and discarded.
The hidden set type is constrained with box, so set values can be reused by
the operations that inspect them.
The hidden type set is never revealed — only its operations are exposed.
Let’s now implement an inefficient, but simple SetModule using lists. This version works for
data elements, because it uses == to check whether an item is already in
the set:
module Main
import {
@core/Bool
@core/Int
@core/List
}
dec ListSet : [type a: data] SetModule<a>
def ListSet = [type a: data] (type List<a>) box case {
.empty => .end!,
.insert(x, set) => .item(x) set,
.contains(y, set) => set.begin.case {
.end! => .false!,
.item(x) xs => {x == y}.case {
.true! => .true!,
.false! => xs.loop,
},
},
}
This implementation of sets can only be constructed for comparable data types. That’s what
a: data ensures here.
We construct the existential by choosing List<a> as the hidden type:
(type List<a>) ...
The consumer of the SetModule doesn’t know that these sets are implemented as lists.
Let’s now use that in a function:
dec Deduplicate : [type a: data, SetModule<a>, List<a>] List<a>
def Deduplicate = [type a: data, (type set: box) mSet, list]
let visited = mSet.empty
in list.begin.case {
.end! => .end!,
.item(x) xs => mSet.contains(x, visited).case {
.true! => xs.loop,
.false! =>
let visited = mSet.insert(x, visited)
in .item(x) xs.loop,
}
}
This function deduplicates a list by tracking seen values using a hidden set implementation.
It doesn’t know how the set works — just that it supports .empty, .insert, and .contains.
Let’s test it!
def IntListSet = ListSet(type Int)
def TestDedup =
Deduplicate(
type Int,
IntListSet,
List.Map(Int.Range(1, 1000), type Int, box [n] Int.Mod(n, 7)),
)
This deduplicates a list of numbers modulo 7 — using:
List.Mapto apply the modulo.ListSetto get an abstract set implementation.Deduplicateto do the filtering.
All without exposing how the set is represented.
Continuation
The continuation type — spelled ? — is the dual of unit.
It has no expression syntax whatsoever — it’s only usable in processes.
Turn the page to learn all about that!
The Big Table
After walking through the individual type chapters, it’s useful to have one compact place where the main constructions and destructions sit side by side.
This chapter is a cheat sheet, not a replacement for the explanations in the earlier chapters. The first table summarizes the expression syntax you’ve already seen.
The second table does the same from the point of view of process syntax. If you haven’t read the next section on process syntax yet, feel free to skip that table for now and come back to it later.
Expression syntax
| Type | Construction | Destruction |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
No expression syntax | No expression syntax |
Process syntax
| Type | Construction | Destruction |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Shown on the left |
The Process Syntax
So far, Par seems clearly a functional language. Yes, it has linear types, and some unusual
features, like choices, and begin/loop for
recursive and iterative types, instead of the
usual recursion by name. But, it’s still clearly a functional language.
However, it is not! At its core, Par is a process language! While functional languages are ultimately based on λ-calculus, Par is based on CP, a process language similar to π-calculus. Process languages are not based on expressions. Instead, they work with concurrent processes, channels, and operations on them, like sending, and receiving. CP was formulated by Phil Wadler, an influential computer scientist, in his wonderful paper called “Propositions as Sessions”. It was not intended to become a basis for a practical programming language; GV — a functional language in the same paper — was supposed to take that role. However, I saw much more potential in CP, and decided to turn it into a practical language.
How is it then that Par managed to look perfectly functional until now? Turns out, all of the construction and destruction syntax described in Types & Their Expressions can actually be considered a syntax sugar over the fundamental process syntax of Par.
While most of the Par code you’ll be writing will use expression syntax, the full power of the language rests in the process syntax. There are things Par can express, which simply are not expressible using the constructs we learned thus far.
What Even Is a Process Language?
The most famous process language is undoubtedly π-calculus. In general, a process language consists of:
- Processes. These are independent units of control flow, that execute concurrently, and interact by communication.
- Channels. That’s where communication happens. Two processes that hold opposite ends of the same channel can use it to exchange information, or even other channels.
- Commands. Processes run by executing commands, those are their code. A command says what interaction to perform on a channel: what to send, what to receive.
From among these, we have already encountered one in Par: channels. That’s because aside from primitives, all values in Par are channels. Yes, functions, pairs, choices, all of them. It will become much clearer as we understand this process syntax.
Processes and commands have been more hidden, so far. They were always there, but not in a plain sight! Any expression, be it a construction, or a destruction, compiled to processes composed of commands.
In fact, you can see it for yourself! Let’s take any Par program, say examples/src/HelloWorld.par.
module HelloWorld
import @basic/Console
def Program = Console.Open
.print("Hello, world!")
.close
Open it in the playground, press Compile, then enable the ✔️ Show compiled checkbox:
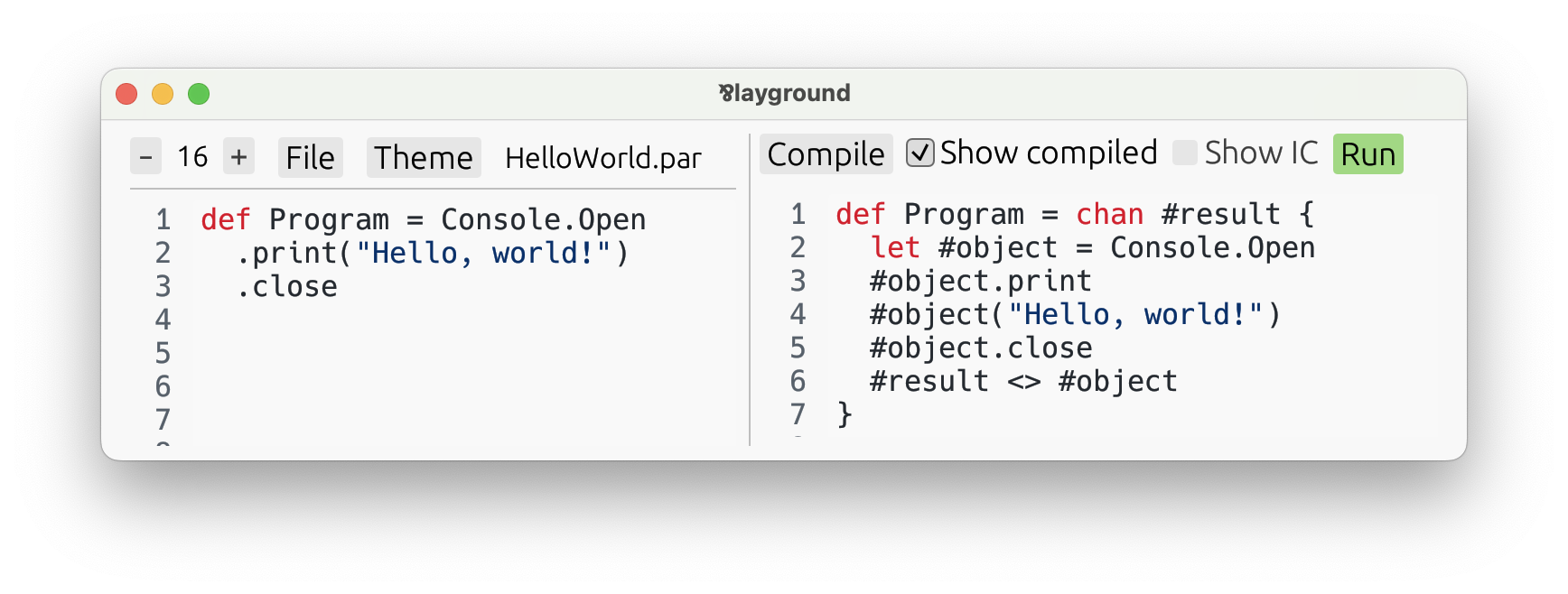
What you see on the right is the same program rewritten using the most bare-bones process syntax that Par offers.
Aside from the #-signs in front of some variables (Par uses them for internally generated variables to avoid
name clashes), this is a valid Par program. If we remove those, we get this:
module HelloWorld
import @basic/Console
def Program = chan result {
let object = Console.Open
object.print
object("Hello, world!")
object.close
result <> object
}
Copy-paste it into the playground and run it! It’s the same program.
Isn’t the expression syntax enough? Why complicate things?
First of all, it is in fact not enough. Not all Par programs are expressible using pure expression syntax, that we’ve learned fully thus far.
But even more importantly, process syntax can make your programs much nicer. It’s not a hammer to be used all the time! Instead, it’s a feature that has to be carefully combined with expression syntax and used when appropriate. Par offers syntax features to seamlessly switch between expressions and processes, so that you can always apply that which fits best, granularly.
Sprinkles of process syntax tend to be a particularly good fit when dealing with choices and iteratives. Take this function that zips two infinite sequences:
type Sequence<a> = iterative choice {
.close => !,
.next => (a) self,
}
dec Zip : [type a, type b, Sequence<a>, Sequence<b>] Sequence<(a, b)!>
def Zip = [type a, type b, seq1, seq2] begin case {
.close =>
let ! = seq1.close in
let ! = seq2.close in !,
.next =>
let (x) seq1 = seq1.next in
let (y) seq2 = seq2.next in
((x, y)!) loop,
}
It takes two sequences, one of as and one of bs, and produces a new sequence of pairs (a, b)!. When asked to close, it
closes the two underlying sequences as well — it must, they are linear. When asked for the next item, it polls both sequences
for their respective items and yields a pair of that.
It works, and is understandable. But, it can be even better, when we apply some process syntax!
dec Zip : [type a, type b, Sequence<a>, Sequence<b>] Sequence<(a, b)!>
def Zip = [type a, type b, seq1, seq2] begin case {
.close => do {
seq1.close
seq2.close
} in !,
.next => do {
seq1.next[x]
seq2.next[y]
} in ((x, y)!) loop,
}
It might not look better on the first sight, due to unfamiliarity. But notice, this version is much less cluttered. Instead
of explicitly re-assigning seq1 and seq2, we simply command them to give us their items. They automatically update in-place.
Here’s where session types come in. We now treat seq1 as a channel. First,
we notify it of our intention with the .next signal. Then, we receive an item and save it to a variable with [x]. The
resemblance to the construction syntax of functions is not a coincidence!
Now, let’s learn what this process syntax is all about! We’ll start by gradually enriching our programs with some commands, all the way to unlocking the full semantics of Par by exploiting duality.
The do Expression
Most of the time, it’s not desirable to use process syntax for the whole program. Instead, it’s usually best to
just insert some commands where appropriate. That’s what the do expression is all about. In real Par programs,
most of the explicit commands will be found in do expressions. And, since we’re already familiar with
expression syntax, do expressions are a good place to start adding commands to otherwise expression-based programs.
A do expression starts with the keyword do, then a sequence of commands (without separators) enclosed in
curly braces, followed by the keyword in, and finally the resulting expression.
It executes the commands first, then evaluates to the expression after in.
def MyName: String = do { } in "Michal"
The above do expression contains no commands, so its result is simply "Michal".
The let Statement
Before getting onto actual commands — those that manipulate channels — there is one non-command that can occur in
a process: the let statement. Just like the let/in expression, it assigns
a variable. The only difference is: the let statement doesn’t contain the in keyword. And, since it’s a process,
there can be more of them one after another.
module Main
import {
@core/Nat
@core/String
}
dec DisplayPlusEquation : [Nat, Nat] String
def DisplayPlusEquation = [a, b] do {
let c = a + b
let a = `#{a}`
let b = `#{b}`
let c = `#{c}`
} in `${a}+${b}=${c}`
def Test = DisplayPlusEquation(3, 4) // = "3+4=7"
This is, in fact, the idiomatic way to assign multiple variables in an expression.
Commands
A process is a sequence of commands, and let statements. Now that we’ve covered
let statements, it’s time to look at commands. We’ll do
that by using them in small, but realistic examples.
First, what even is a command? It’s similar to a statement in imperative programming, but there is an important difference. In imperative programming, a statement is usually an expression that’s evaluated not for its result, but for its side-effects. In contrast, commands in Par are not expressions, they are a distinct syntactic category.
Every command has a subject, a channel — usually a local variable — that the command is operating on. After executing the command, the subject changes its type. This is the important distinction from imperative statements. It’s the distinction that brings proper, and ergonomic session typing to this imperative-looking process syntax.
Let’s see that in action!
Selecting & Sending
The built-in String.Builder type is defined this way:
type String.Builder = iterative choice {
.add(String) => self,
.build => String,
}
It’s basically an object, in an OOP-fashion, with two methods: .add and .build. At the top
level, it’s an iterative choice: an object that
can be repeatedly interacted with.
We construct an empty String.Builder using the built-in definition of the same name:
module Main
import @core/String
def LetsBuildStrings = do {
let builder = String.Builder
// code continued below...
Selection
Now, we have a local variable builder of the type String.Builder.
When learning about iterative types, we learned that we can treat them
as their underlying body. For String.Builder, it’s a choice type, and the command for those is
the selection command.
All commands start with their subject. Here it’s the builder variable. The selection command
itself then looks the same as the usual destruction of a choice.
def LetsBuildStrings = do {
let builder = String.Builder
builder.add // selection command
// code continued below...
That’s it! Now, here’s the crucial bit: after selection, builder changes its type to the type
of the selected branch. Here’s the one we selected:
.add(String) => self,
The argument on the left side of => is just a syntax sugar for a function.
De-sugared, it is:
.add => [String] self,
Therefore, the type of builder after this builder.add command becomes a function:
builder: [String] iterative choice {
.add(String) => self,
.build => String,
}
The
selfin the original branch got replaced by its correspondingiterative— in this case, the originalString.Builder.
Sending
For a function type, we have the send command. It’s just like a function call — but as a command, it doesn’t have a result. Instead, it turns the subject itself to the result.
def LetsBuildStrings = do {
let builder = String.Builder
builder.add // selection command
builder("Hello") // send command
You may have noticed, that the selection and send commands behave the same as a combination of a regular destruction and re-assignment of the variable. In code:
let builder = builder.add let builder = builder("Hello")For these two, the behavior matches perfectly! It’s a good way to build intuition about what these commands mean. However, this simple translation stops working as we get into the
.caseand receive commands.
After sending the string, builder turns back into the original String.Builder, so we can
keep adding more content to it.
def LetsBuildStrings = do {
let builder = String.Builder
builder.add // selection command
builder("Hello") // send command
builder.add // selection command
builder(", ") // send command
builder.add // selection command
builder("World") // send command
builder.add // selection command
builder("!") // send command
Chaining commands
This is rather noisy, but we can improve it! Multiple consecutive commands on the same subject, can be chained together, without repeating the subject.
module Main
import @core/String
def LetsBuildStrings = do {
let builder = String.Builder
builder.add("Hello")
builder.add(", ")
builder.add("World")
builder.add("!")
Or even:
def LetsBuildStrings = do {
let builder = String.Builder
builder
.add("Hello")
.add(", ")
.add("World")
.add("!")
I like the first variant better, though.
To complete the do expression, let’s just return the constructed string:
def LetsBuildStrings = do {
let builder = String.Builder
builder.add("Hello")
builder.add(", ")
builder.add("World")
builder.add("!")
} in builder.build // = "Hello, world!"
Looping & Branching
We’ve now seen how commands work with choice types (via selection), and function types (via sending). But those aren’t the only types that come with their own command styles. Every type does.
Let’s turn our attention to something more intricate: recursive types.
Take this familiar definition:
type List<a> = recursive either {
.end!,
.item(a) self,
}
The List type is recursive, and contains an
either, and within that, a pair.
To work with such a structure in process syntax, we’ll need to combine three kinds of commands:
.beginand.loopfor recursion,.casebranching on the either,- And
value[variable]for receiving (peeling off) a value from a pair.
We’re now going to demonstrate all of these by implementing a string concatenation function.
module Main
import {
@core/List
@core/String
}
dec Concat : [List<String>] String
This function takes a list of strings, and returns them concatenated. We’ll use process syntax and see how it works out!
def Concat = [strings] do {
// code continued below...
Let’s go step by step!
Recursion in processes
We start by telling the process: “Hey, we’re about to work with a recursive value!”
That’s what .begin does. It establishes a looping point, to which we can jump back later
using .loop.
strings.begin
Branching
The .case command behaves similarly to expression-based .case, but with two key differences:
In process syntax, the body of each .case branch is a process, not a value.
This means the syntax requires curly braces after the =>. You do something in each branch —
not return something.
strings.case {
.end! => {
// empty list, nothing to do
}
.item => {
There’s another key difference: notice the .item branch has => right after the branch name!
There’s no pattern. That’s because in process syntax, binding the payload of an
either is optional. Normally, the subject itself becomes the payload.
However, it is possible to match the payload fully, if desired.
So, inside the .item branch, strings now has the type (String) List<String> — it’s a pair, and
we want to peel off its first part, to add it to the string builder.
There’s one last important detail, and that’s concerning control flow. If a .case
branch process does not end (we’ll learn about ending processes in the section about
chan expressions), then it proceeds to the next line after the closing
parenthesis of the .case command. All local variables are kept.
Receiving
To peel a value from a pair, we use the receive command:
strings[str]
This command says:
“Take the first part of the pair and store it in str. Keep the rest as the new value of strings.”
Now we can assemble the basic skeleton:
def Concat = [strings] do {
let builder = String.Builder
strings.begin.case {
.end! => {
// nothing to do
}
.item => {
strings[str]
builder.add(str)
strings.loop
}
}
} in builder.build
This looks very imperative! The variable strings flows through the process —
branching, unwrapping, and looping — without needing to be reassigned. It performs all the
different operations based on its changing type. Meanwhile, builder accumulates the result,
tagging along the control flow of strings.
Patterns in .case branches
The .item => branch can be made a little more pleasant. If the subject after .begin is a
pair, we’re allowed to use pattern matching directly in the .case branch.
That means this:
.item => {
strings[str]
builder.add(str)
strings.loop
}
Can be rewritten as:
.item(str) => {
builder.add(str)
strings.loop
}
Which is exactly what we’ll do in the final version:
module Main
import {
@core/List
@core/String
}
dec Concat : [List<String>] String
def Concat = [strings] do {
let builder = String.Builder
strings.begin.case {
.end! => {}
.item(str) => {
builder.add(str)
strings.loop
}
}
} in builder.build
def TestConcat = Concat(*("A", "B", "C")) // = "ABC"
This beautifully ties together all the commands we’ve covered so far:
- Selection for choices.
- Sending for functions.
- Branching for eithers.
- Receiving for pairs. Here, in the form of a pattern.
The receive commands is the least clearly useful here. Let’s move to infinite sequences to see a more compelling use-case.
Receiving, Where It Shines
The previous section showed the value[variable] receive command — but it didn’t feel essential.
Let’s now explore a use-case where this command really shines: polling values from an
infinite sequence.
You may remember the Sequence<a> type from earlier. Here’s the definition again:
type Sequence<a> = iterative choice {
.close => !,
.next => (a) self,
}
A Sequence can generate an unbounded number of values, one by one, and eventually be closed.
A Fibonacci sequence, as a value
Let’s start by building a sequence of Fibonacci numbers.
dec Fibonacci : Sequence<Nat>
def Fibonacci =
let (a) b = (0) 1
in begin case {
.close => !
.next =>
let (a) b = (b) {a + b}
in (a) loop
}
The internal state of the sequence is a pair (a) b. On each .next, we emit a and update
the pair. This is a clean and elegant use of corecursive iteration, as we’ve covered it in the
section on iterative types.
So far so good — but how do we use this value?
Goal: print the first 30 Fibonacci numbers
Let’s say we want to print the first 30 Fibonacci numbers to the terminal.
That means:
- Repeating an action 30 times,
- Receiving a number from the sequence each time,
- Converting it to a string,
- Sending it to the output.
We’ll need a way to loop exactly 30 times. But there’s a catch: In Par,
looping is only possible on recursive types. There’s no built-in recursion on Nat, so we need
to convert the number 30 into a recursive.
Good news: there’s a built-in helper for that! It’s called Nat.Repeat, here’s its type:
dec Nat.Repeat : [Nat] recursive either {
.end!,
.step self,
}
Calling Nat.Repeat(30) gives us a recursive value that can be stepped through exactly 30 times.
Precisely what we need.
Now for the second part: printing.
Console output
Par comes with a built-in definition for working with standard output:
def Console.Open : Console
The Console type itself is defined like this:
type Console = iterative choice {
.close => !,
.print(String) => self,
}
You can think of it as a “sink” object that receives strings and sends them to the terminal.
Much like String.Builder, but the output appears directly in your console.
Let’s tie it all together!
module Main
import {
@basic/Console
@core/Nat
}
def Program: ! = do {
let console = Console.Open
let fib = Fibonacci
Nat.Repeat(30).begin.case {
.end! => {}
.step remaining => {
fib.next[n]
console.print(`#{n}`)
remaining.loop
}
}
fib.close
console.close
} in !
Here’s what’s happening:
Nat.Repeat(30)becomes the subject of the.beginand.casecommands.- In each
.step, we receive a number from thefibsequence using thefib.next[n]command. - We convert it to a string with a template string and print it to the console.
- Then we
loop.
The fib.next[n] line is where receive command truly shines. It receives the payload
of the .next branch — a number — and updates fib to the rest of the sequence. Note, that
it’s a combination of two commands: a selection and a receive.
Once done, we close both the sequence and the console. We must, they are linear.
Channels & Linking
In the previous sections, we built up values using the do/in expressions:
def Message = do {
let builder = String.Builder
builder.add("Hello")
builder.add(", ")
builder.add("World")
} in builder.build
This form lets you run a process — a sequence of commands — and then return a final expression at the end.
But what if you want to return early, based on some logic? Par has no return keyword. But it does have a deeper mechanism that allows exactly this — and more.
The do/in syntax is just sugar for something more fundamental: the chan expression,
combined with a command called linking. This:
do {
<process>
} in <value>
is exactly the same as:
chan result {
<process>
result <> <value>
}
Let’s unpack what this means.
The chan Expression
chan inner {
// commands here
}
This expression creates a new channel, and spawns a process that runs the commands inside the
curly braces. That process is given access to one endpoint of the new channel —
named here as inner.
The chan expression itself evaluates to the other endpoint of the channel — that’s the value
the expression returns.
The key is this: If the whole chan expression has type T, then inside the block, inner
has type dual T.
We’ll explore the details of dual types in the next section, but for now, here’s the intuition: A type and its dual are two opposite side of communication. If one side offers something, the other one requires it, and vice versa.
For example, if the whole chan expression should evaluate to an Int, then dual Int is
a requirement of an integer.
Linking — the <> command
The link command is the simplest way to fulfill that requirement. If x has type T
and y has type dual T, then:
x <> y
Connects the two endpoints, and ends the process.
For example:
def FortyTwo: Int = chan out {
out <> 42
}
This returns the number 42, using a full process.
Like all commands, <> operates on values — here, two channels — not processes.
You’re not linking a process to a value. You’re linking one channel to another.
Processes in
chanmust end. Every process inside achanmust end with one of two commands:
- A link command (x <> y), or
- A break command (x!), which we’ll meet in the next section.
These are the only ways a process can terminate. If you reach the end of a
chanblock without either one, it’s an error. This may seem a strange condition, but it’s important for some concurrency invariants Par provides.In contrast,
do/inblocks don’t end themselves — they continue into the expression afterin.
Let’s write a function that can use that early return.
It takes a natural number (Nat) and returns a String.
- If the number is zero, it returns the string
"<nothing>". - Otherwise, it returns a string of exactly
nhash marks ("#").
Here’s how that looks:
module Main
import {
@core/Nat
@core/String
}
dec HashesOrNothing : [Nat] String
def HashesOrNothing = [n] chan result {
{n == 0}.case {
.true! => {
result <> "<nothing>"
}
.false! => {}
}
let builder = String.Builder
Nat.Repeat(n).begin.case {
.end! => {}
.step remaining => {
builder.add("#")
remaining.loop
}
}
result <> builder.build
}
Let’s break this down:
n == 0returns aBool, which is aneitherwith branches.true!and.false!.- In the
.true!branch, we immediately perform a link — returning"<nothing>". Note, that this ends the process. - The
.false!branch does nothing on its own — the real work happens after the.case. - We build the result using a
String.Builder, looping exactlyntimes usingNat.Repeat. - Finally, we link the builder’s result to
result, ending the process.
In the next section, we’ll learn how to exploit duality, to not just return, but sequentially build on the opposing channels!
Construction by Destruction
We’ve now seen the chan expression in action, using the obtained channel to return early
in its process. But that only scratches the surface!
The channel you obtain isn’t just a return handle — it’s a direct connection to the consumer of the result. It can be interacted with sequentially, constructing a value step-by-step.
The title of this section, “construction by destruction”, is very apt! What we’re about to learn here is exactly analogous to the famous trick in mathematics: a proof by contradiction. And, it’s just as powerful.
Duality in theory
Every type in Par has a dual — the opposite role in communication.
There is a type operator, dual <type>, which transforms a type to its dual. Here’s how
it’s defined structurally:
dual !
|
= | ?
|
dual ?
|
= | !
|
dual (A) B
|
= | [A] dual B
|
dual [A] B
|
= | (A) dual B
|
|
= | |
|
= | |
dual recursive F<self>
|
= | iterative dual F<dual self>
|
dual iterative F<self>
|
= | recursive dual F<dual self>
|
dual [type a] F<a>
|
= | (type a) dual F<a>
|
dual (type a) F<a>
|
= | [type a] dual F<a>
|
Don’t worry if the
F<...>in recursive and generic types looks intimidating. It’s just a way to formalize that after flipping fromrecursivetoiterative(and similarly in the other cases), we continue dualizing the body.”.
Looking at the table, here’s what we can see:
- Units are dual to continuations.
- Functions are dual to pairs.
- Eithers are dual to choices.
- Recursives are dual to iteratives.
- Foralls are dual to existentials.
- The duality always goes both ways!
The last point is important. It’s a fact, in general, that dual dual A is equal to A.
Duality in action
Here’s a familiar definition:
type List<a> = recursive either {
.end!,
.item(a) self,
}
So, what’s its dual? Applying the above rules, we get:
iterative choice {
.end => ?,
.item(a) => self,
}
While a List<a> provides items, until it reaches the end, its dual requires you to
give items (via the .item branch), or signal the end. Whoever is consuming a list,
this dual type provides a good way to communicate with them.
Notice the ? in the .end branch. That’s a continuation. There is no expression syntax for
this type, but finally, we’re going to learn how to handle it in processes!
Remember: in a chan, the channel you obtain inside the block always has the dual type of the expression’s
final result. Let’s use this to construct a list step-by-step.
module Main
import {
@core/Int
@core/List
}
def SmallList: List<Int> = chan yield {
yield.item(1)
yield.item(2)
yield.item(3)
yield.end
yield!
}
// def SmallList = *(1, 2, 3)
This is just a usual handling of an iterative choice, except for the last line.
Selecting the .end branch transforms the yield channel into a ? — the continuation type. At that point,
the protocol is over, and only one command is valid: a break. It’s spelled !, that’s the last line:
yield! // break here
Like linking, it has to be the last command in a process. In fact, link and break are the only ways to end a process.
A real example: flattening a list of lists
Let’s now use this style to implement something meaningful. We’ll write a function that flattens a nested list:
dec Flatten : [type a, List<List<a>>] List<a>
It’s a generic function, using the forall for polymorphism.
Here’s the full implementation, imperative-style:
def Flatten = [type a, lists] chan yield {
lists.begin@outer.case {
.end! => {
yield.end!
}
.item(list) => {
list.begin@inner.case {
.end! => {}
.item(value) => {
yield.item(value)
list.loop@inner
}
}
lists.loop@outer
}
}
}
It makes a bunch of concepts we’ve already covered come together.
- We loop through the outer list of lists using
.begin@outerand.loop@outer. - If it’s
.end!, we finish:yield.end!. - If it’s
.item(list), we then begin looping through the inner list.- We don’t manually bind the remainder of the list — the communication simply continues on
the original variable:
lists. - The nested
.begin/.loopshines here; no helper functions needed.
- We don’t manually bind the remainder of the list — the communication simply continues on
the original variable:
- In the inner loop:
- If it’s
.end!, we’re done with that list — we continue the outer loop. - If it’s
.item(value), we yield it to the consumer withyield.item(value), then loop again. Re-binding of the rest of the list is not needed here, either.
- If it’s
Duality combined with the chan expressions gives us a lot of expressivity.
Constructing lists generator-style is just one of the use-cases.
Whenever it feels more appropriate to become a value instead of constructing it from parts, chan and
duality come to the task!
Quality of Life Syntax Sugar
Par gives you a set of very light core constructs. Everything else is built on those foundations. Some bits of syntax, though, exist purely to make common patterns less noisy.
Error Handling
Programs that interact with the real world must handle errors gracefully. Files don’t exist, networks disconnect, users type unexpected input. Most errors occur at I/O boundaries where your program meets external systems beyond its control.
Par takes a structured approach to error handling that builds on its linear type system. At its core, Par uses explicit Result types — but adds lightweight syntax sugar that makes working with errors feel natural while keeping the underlying semantics transparent.
Why Par Needs Unique Error Handling
Par’s linear type system together with its concurrent evaluation creates a unique situation for error handling. Traditional approaches don’t work for Par:
Exceptions propagate across call stacks, unwinding through multiple function calls automatically. But Par’s concurrent execution model has no call stacks! Instead, it has processes that communicate via channels. Any error must be explicitly passed via a channel, making something like a Result type necessary for error handling.
Rust’s ? operator works by dropping remaining owned values when propagating errors. This implicit cleanup doesn’t translate to Par’s linear types, where each value must be consumed according to its specific type and context.
Par needs error handling that makes cleanup fully explicit while remaining convenient to use. The try/catch/throw syntax sugar introduced here achieves this balance — borrowing familiar keywords from exception handling while operating very differently. Unlike traditional exceptions, Par’s error handling is purely local syntax sugar over Result types, with no hidden control flow or stack unwinding.
Working with Files: Error Handling Without Sugar
Let’s start with a concrete example using Par’s file system operations through the built-in @basic/Os module. The Os.Path type provides methods for working with the filesystem — creating files, reading directories, and so on. Most of these operations can fail, so they return Result values.
Here’s what error handling looks like without any syntax sugar. We’ll write a program that creates a log file and writes some entries to it:
module Main
import {
@basic/Console
@basic/Os
}
def Main: ! = chan exit {
let console = Console.Open
let path = Os.Path("logs.txt")
path.createOrAppendToFile.case {
.err e => {
console.print(e)
console.close
exit!
}
.ok writer => {}
}
// ...
A few things to note about this pattern:
The chan exit creates a channel called exit of type ? — the continuation type, which is dual to our Main function’s return type !. The exit! syntax is the break command applied to this continuation, which ends the process.
After the .case block, the writer variable is available in the surrounding scope. This is how process-scoped variables work in Par — variables bound in .case branches continue to exist after the case analysis.
writer.write("[INFO] First new log\n").case {
.err e => {
console.print(e)
console.close
exit!
}
.ok => {}
}
In process syntax, when we use .ok =>, the subject of the command (writer) gets updated to the payload of the .ok branch. Since .write returns the same Os.Writer type on success, writer remains usable.
writer.write("[INFO] Second new log\n").case {
.err e => {
console.print(e)
console.close
exit!
}
.ok => {}
}
And finish by closing the file:
writer.close.case {
.err e => {
console.print(e)
console.close
exit!
}
.ok! => {}
}
exit!
}
Note the .ok! pattern here — after closing, the writer becomes a unit value !.
Here’s the complete program:
module Main
import {
@basic/Console
@basic/Os
}
def Main: ! = chan exit {
let console = Console.Open
let path = Os.Path("logs.txt")
path.createOrAppendToFile.case {
.err e => {
console.print(e)
console.close
exit!
}
.ok writer => {}
}
writer.write("[INFO] First new log\n").case {
.err e => {
console.print(e)
console.close
exit!
}
.ok => {}
}
writer.write("[INFO] Second new log\n").case {
.err e => {
console.print(e)
console.close
exit!
}
.ok => {}
}
writer.close.case {
.err e => {
console.print(e)
console.close
exit!
}
.ok! => {}
}
console.close
exit!
}
This is extremely verbose! The same error handling code is repeated for every operation that might fail. Let’s see how Par’s error handling sugar can clean this up.
The Same Program with try/catch
Here’s the exact same functionality using Par’s error handling syntax:
module Main
import {
@basic/Console
@basic/Os
}
def Main: ! = chan exit {
let console = Console.Open
catch e => {
console.print(e)
console.close
exit!
}
let path = Os.Path("logs.txt")
let try writer = path.createOrAppendToFile
writer.write("[INFO] First new log\n").try
writer.write("[INFO] Second new log\n").try
writer.close.try
console.close
exit!
}
Significantly shorter and more readable! The error handling is declared once and applies to all subsequent operations.
How try/catch/throw Work in Process Syntax
Par’s error handling sugar is built around small, local keywords that desugar to explicit Result handling. Let’s understand how they work.
The catch Statement
Before you can use try or throw, you must define a catch block in the same process. This restriction is crucial — the corresponding try and throw commands must be in the same sequential process as their catch, not in nested processes or expressions.
catch <pattern> => {
<process>
}
The <pattern> can be any pattern like those used in let statements or function parameters. Usually this is a simple variable name, but you can use more complex patterns when needed.
For example, if the error type is unit:
catch ! => { ... }
You can also include type annotations:
catch e: Os.Error => { ... }
The <process> inside a catch block must end with a process-ending command:
- break:
continuation! - linking:
left <> right .loopto return to a .begin that’s outside the catch block, useful for retrying operationsthrowto jump to anothercatchblock
The throw Command
throw jumps directly to a catch block with an error value:
catch e => {
console.print(e)
console.close
exit!
}
throw "Total meltdown"
This is equivalent to executing the catch block directly:
console.print("Total meltdown")
console.close
exit!
throw is useful for creating custom error conditions in your logic.
The try Patterns and Commands
The real power comes from try, which provides conditional error handling based on Result values:
type Result<e, a> = either {
.err e,
.ok a,
}
try appears in two contexts: patterns and commands.
.try in Commands
The .try postfix transforms verbose Result case analysis into clean linear code. Remember our original verbose version:
writer.write("[INFO] First new log\n").case {
.err e => {
console.print(e)
console.close
exit!
}
.ok => {}
}
With .try, this becomes:
writer.write("[INFO] First new log\n").try
The .try postfix desugars any command or expression returning a Result:
variable.try
becomes:
variable.case {
.err e => {
throw e
}
.ok => {}
}
This works for more complex command chains too. Consider this type for polling data with possible errors:
type Poll<e, a> = iterative choice {
.close => Result<e, !>,
.poll => Result<e, (a) self>,
}
You can poll an element and handle errors seamlessly:
// source : Poll<Os.Error, String>
source.poll.try[value]
After this command, source maintains its Poll<Os.Error, String> type and value contains the successfully polled String.
The Concurrent Evaluation Restriction
You might think this would work:
let writer = path.createOrAppendToFile.try
However, this causes a type error. The reason reveals something fundamental about Par’s evaluation model.
Par evaluates expressions concurrently with the processes that use them. When you write:
let writer = path.createOrAppendToFile.try
The expression path.createOrAppendToFile runs concurrently with the process doing the let. If the expression were to fail on .try, the main process might already be executing other commands — there’s no sound way to “rewind” that execution.
This is why try and throw can only be used in the same process as their corresponding catch, not in nested expressions or processes.
try in Patterns
The solution is to use try in the pattern itself:
let try writer = path.createOrAppendToFile
This moves the error handling into the correct process. The desugaring is:
let writer = path.createOrAppendToFile
writer.case {
.err e => {
throw e
}
.ok => {}
}
Since try is part of the pattern, it works in nested patterns too:
let (try leftReader, try rightReader)! = (
leftPath.openFile,
rightPath.openFile,
)!
And it works in receive commands, too. The Console type demonstrates this well:
type Console = iterative choice {
.close => !,
.print(String) => self,
.prompt(String) => (Result<!, String>) self,
}
The .prompt method returns a Result while keeping the console alive for more operations:
let console = Console.Open
catch ! => {
console.print("Failed to read input.")
console.close
exit!
}
console.prompt("What's your name?")[try name]
console.prompt("What's your address?")[try address]
Error Handling in Expression Syntax
Par also supports try/catch directly in expressions, with syntax adapted for expression contexts:
catch <pattern> => <err result> in <expression using try/throw>
The same concurrent evaluation restrictions apply, with an additional constraint: try/throw can only be used before any part of the result is constructed.
This is invalid because result.try appears in a nested expression, which runs as a separate concurrent process:
// result : Result<String, Int>
catch e => .err e in
.ok {result.try + 1}
This fix attempts to work around the nested expression issue but still fails — the outer .ok constructs part of the result before try executes:
catch e => .err e in
.ok let try value = result in
value + 1
Here’s the correct version:
catch e => .err e in
let try value = result in
.ok {value + 1}
This ensures all error handling completes before constructing the result.
Useful Expression Patterns
Expression-form catch enables several common patterns:
Mapping the error (adding context):
catch e => .err String.Builder.add("Failed to process file: ").add(e).build in
let try content = file.readAll in
.ok ProcessContent(content)
Mapping the success value:
catch e => .err e in
let try rawData = source.fetch in
.ok Encode(rawData)
Unwrapping with a default value:
catch ! => "Unknown" in
config.getUserName.try
Labels and Layered Error Handling
Like begin/loop, catch blocks can be labeled for precise control:
catch@label e => { ... }
The corresponding try and throw commands reference the same label:
let try@label value = result
throw@label "Custom error"
Labels are selected by proximity and name, not by error type. The nearest catch with the matching label (or no label) is chosen. This allows different error types to be routed to different handlers:
catch@fs e => { /* handle file system errors */ }
catch@net e => { /* handle network errors */ }
let try@fs writer = path.createFile
let try@net conn = url.connect
Throwing to Previous catch Blocks
A powerful pattern is using nested catch blocks for resource cleanup while delegating to outer blocks for shared error handling.
Here’s a simple example showing the basic pattern:
catch e => {
Debug.Log("Main error handler")
Debug.Log(e)
exit!
}
let try resource = AcquireResource
catch e => {
resource.cleanup
throw e // delegate to the main handler above
}
// use resource, but error might occur elsewhere
let try otherData = SomeOtherOperation // this might fail
ProcessTogether(resource, otherData)
The inner catch handles cleanup of the specific resource, then throws to the outer catch for shared error reporting logic. The key point is that the error occurs in SomeOtherOperation, not in the resource itself, so the resource is still valid and needs proper cleanup.
Here’s this pattern in a more complex, real-world example — copying a file with proper resource management:
def Main: ! = chan exit {
let console = Console.Open
catch ! => { console.print("Failed to read input.").close; exit! }
console.prompt("Src path: ")[try src]
console.prompt("Dst path: ")[try dst]
catch e: Os.Error => {
console.print("An error occurred:")
console.print(e)
console.close
exit!
}
let try reader = Os.Path(src).openFile
catch@w e => { reader.close; throw e }
let try@w writer = Os.Path(dst).createOrReplaceFile
catch@r e => { writer.close; throw e }
reader.begin.read.try@r.case {
.end! => {
writer.close.try
console.close
exit!
}
.chunk(bytes) => {
writer.write(bytes).try@w
reader.loop
}
}
}
Here, the catch@r and catch@w blocks provide resource-specific cleanup (closing file handles) but then throw to the main error handler for shared logic like printing the error and exiting.
This layered approach allows you to build sophisticated error handling hierarchies while keeping each level focused and clear.
Propagating Errors in Functions
The examples so far have shown terminal error handling — printing errors and exiting. But often you want to propagate errors up to the caller. Here’s a utility function that reads an entire file’s contents:
module Main
import {
@basic/Os
@core/Bytes
@core/Result
}
dec ReadAll : [Os.Path] Result<Os.Error, Bytes>
def ReadAll = [path] chan return {
catch e => { return <> .err e }
let try reader = path.openFile
let parser = Bytes.ParserFromReader(reader)
let try contents = parser.remainder
return <> .ok contents
}
This function uses Bytes.ParserFromReader to convert the chunked Bytes.Reader from path.openFile into a parser that provides a convenient .remainder method for reading all contents at once. The catch block propagates any errors by linking them into an .err result, while success links the contents into an .ok result.
Providing defaults with default
Sometimes you don’t want to propagate an error — you want to replace it with a fallback and keep going. The default sugar does exactly that, and unlike try, it is completely standalone: it does not require a surrounding catch, and it is valid even in nested expression positions.
-
Postfix form (expressions/commands):
let r1: Result<!, Int> = .ok 7 let r2: Result<!, Int> = .err! let x = r1.default(0) // x = 7 let y = r2.default(0) // y = 0This desugars to a
.caseon the subject: on.okit continues with the unwrapped value, on.errit evaluates the fallback expression and uses that value instead. Because it is a local rewrite, it can be used directly inletbindings and other expression contexts. -
Pattern form (including in receives):
let default(0) n = Nat.FromString("oops")The pattern binds on
.ok, and binds the fallback expression on.err.Here’s a practical example that shows why the pattern form is particularly useful with receive commands. It counts word occurrences using a map; when a key is missing, it starts from
0:dec Counts : [List<String>] List<(String) Nat> def Counts = [words] do { let counts = Map.New(type String, type Nat) words.begin.case { .end! => {} .item(word) => { counts.entry(word)[default(0) count] counts.put(count + 1) words.loop } } } in counts.listIn the
.itembranch,counts.entry(word)returns aResult<!, Nat>via a receive;default(0)seamlessly handles the missing case and bindscountto0.
Conditions & if
Par has if in both expression syntax (it returns a value) and process syntax
(it runs process code). What makes Par’s if unusual is the condition language:
conditions can match eithers and bind names, and those bindings flow through
and/or/not.
We’ll start with a tiny if you can read left to right, then grow it into the
full condition language, and finally see how the same ideas apply in process
code.
Expression if { ... }
Let’s start with a small example:
module Main
import {
@core/Bool
@core/String
}
dec Describe : [Bool] String
def Describe = [flag] if {
flag => "on",
else => "off",
}
Read the syntax left to right:
if {starts the conditional expression.- A branch is
<condition> => <expression>. - Branches are separated by commas.
else => ...is the fallback branch.- The closing
}ends the expression.
In other words:
if {
<condition> => <expression>,
...
else => <expression>,
}
Values of the Bool type (an either { .true!, .false! }) can be used directly
as conditions, so any expression producing Bool can be used on the left of
=>.
Unlike the common if ... else if ... else chain found in many languages, Par’s
“normal” if is a single if { ... } block with any number of branches.
To evaluate an if { ... }, read it like this:
- Check branches from top to bottom.
- For each branch, evaluate its condition.
- The first condition that succeeds selects its branch, and the
ifevaluates to that branch’s expression. - If no condition succeeds, the
elsebranch is chosen.
is: matching an either (and binding)
Par’s “sum type” is either. If you just want to match an
either without extra predicates, you can always use .case. if becomes
useful once you want to match and filter while keeping bindings.
Two common either types you’ll see everywhere are Result and Option:
type Result<e, a> = either {
.err e,
.ok a,
}
type Option<a> = Result<!, a>
An is condition checks an either and binds its payload. Its shape is:
<value> is .<variant><payload-pattern>
The payload pattern is always present. For a unit payload you still write !,
so value is .less! is valid, but value is .less is not.
The comparison operators are powered by a generic comparison function whose result type is
Ordering:
type Ordering = either {
.less!,
.equal!,
.greater!,
}
Now an if can match directly on those variants:
module Main
import {
@core/Data
@core/Int
@core/String
}
dec CompareSign : [Int, Int] String
def CompareSign = [x, y]
let cmp = Data.Compare((x) y) in
if {
cmp is .less! => "less",
cmp is .greater! => "greater",
else => "equal",
}
Read it top to bottom:
- If
cmp is .less!succeeds, the wholeifbecomes"less". - Otherwise, if
cmp is .greater!succeeds, the wholeifbecomes"greater". - Otherwise it falls through to
elseand becomes"equal".
is only works with either types. You cannot write is 5 or match arbitrary
values; use normal boolean expressions for those.
and: match, then refine
In Par, and/or/not are not just boolean algebra operators. They are
control-flow constructs: they short-circuit, and those success/failure paths are
how bindings from is become available (or not available) later in the
condition and inside the branch.
and with an extra predicate
dec CountStatus : [Option<Nat>] String
def CountStatus = [count] if {
count is .ok n and n == 0 => "zero",
count is .ok _ => "non-zero",
else => "missing",
}
Step by step:
- Try the first branch.
- First evaluate
count is .ok n. If it fails, the wholeandfails. - If it succeeds,
nis bound and Par evaluatesn == 0. - Only if both parts succeed does the branch return
"zero".
- First evaluate
- If the first branch fails, try the second branch
count is .ok _, which matches any present value and returns"non-zero". - If both branches fail,
countmust be.err!, soelsereturns"missing".
and with two bindings
dec AddOk : [Result<String, Int>, Result<String, Int>] Int
def AddOk = [left, right] if {
left is .ok a and right is .ok b => a + b,
else => 0,
}
If the whole condition succeeds, it means both matches succeeded, so both a
and b are in scope in the branch.
Read it like this:
- Try to bind
afromleft. - Only if that succeeds, try to bind
bfromright. - Only if both succeed does the branch run
a + b.
or: try one condition, then another
Like and, or short-circuits. The right side only runs if the left side
fails. A good mental model is:
try the left condition; if it fails, try the right condition
One common use for or is “fallback” matching:
dec PickOk : [Result<String, String>, Result<String, String>] String
def PickOk = [primary, fallback] if {
primary is .ok value or fallback is .ok value => value,
else => "<missing>",
}
Read it as two attempts:
- Try
primary is .ok value. - Only if that fails, try
fallback is .ok value. - If either succeeds, the branch runs and returns
value.
If you want to use a binding after an or, bind the same name on every
success path (as above). If the two sides bind different names, neither name is
guaranteed to exist after the or.
Grouping conditions with { ... }
not, and, and or have precedence (not > and > or). To make
grouping explicit, you can use { ... } inside a condition:
dec EmptyOrSpace : [Result<String, String>] Bool
def EmptyOrSpace = [result] if {
result is .ok s and { s == "" or s == " " }
=> .true!,
else => .false!,
}
These braces group the condition. They are different from the braces after
if in if { ... }, which contain the branches.
not: bindings move to the failure path
not is different from most languages here: it flips success and failure, and
that flip also affects bindings. Any bindings introduced inside the condition
end up on the failure path of not.
dec UseOrError : [Result<String, String>] String
def UseOrError = [result] if {
not result is .ok value => "error",
else => value,
}
Read it carefully:
result is .ok valuewould succeed on.ok value.notflips success and failure.- So the
elsebranch is the path whereresult is .ok valueholds, andvalueis available there.
Because or only evaluates its right side when the left side fails, you can
combine not and or in a way that “unlocks” bindings on the right:
dec NonEmptyOrError : [Result<String, String>] String
def NonEmptyOrError = [result] if {
not result is .ok str or str == "" => "bad input",
else => str,
}
Follow the control flow:
- First evaluate
not result is .ok str. - The right side
str == ""runs only if the left side fails. - The left side fails exactly when
result is .ok strsucceeds. - That is why
stris available on the right side and in theelsebranch.
This also works with grouped conditions:
dec AddBothOrZero : [Result<String, Int>, Result<String, Int>] Int
def AddBothOrZero = [left, right] if {
not { left is .ok x and right is .ok y } => 0,
else => x + y,
}
Read it the same way: x and y are bound by the condition inside { ... },
and because of not, they become available on the else path.
A quick comparison (Java Optional)
In Java, the same idea often becomes “check, then get”:
if (result.isEmpty() || result.get().isEmpty()) {
log("bad input");
return;
}
var str = result.get();
log(str);
Par keeps the match and the predicate together in one place.
Standalone boolean expressions
You can also compute booleans directly:
let ok = left or right
Bindings created inside such a boolean expression stay inside that expression:
let ok = result is .ok msg and msg == ""
// `msg` is not available here
Use if when you want bindings to escape into a branch.
if in process syntax
In process syntax, branches contain process code in braces, and execution can
fall through after the if.
The multi-branch form looks like:
if {
<condition> => { <process> }
...
else => { <process> }
}
(No commas here — branches are separated by whitespace, like .case { ... }.)
If you haven’t seen process syntax yet, start with The Process Syntax.
In short: do { ... } in expr runs the process inside the braces, then
continues as the expression after in.
dec Show : [Result<String, String>] !
def Show = [result] do {
if {
result is .ok msg => { Debug.Log(msg) }
else => { Debug.Log("bad") }
}
Debug.Log("after") // fallthrough
} in !
Just like in the expression form, branches are checked top to bottom and the
first matching branch runs. After the if { ... } finishes, the process
continues with the fallthrough code.
Single-condition process if
There is also a special single-condition form:
if <condition> => { <process> }
<more process code>
Here <more process code> acts as the else branch and also as the
fallthrough, which is great for early exits.
This is a very common style for guard clauses: “if the input is bad, exit; otherwise continue”.
dec DefaultIfEmpty : [String] String
def DefaultIfEmpty = [text] chan out {
if text == "" => {
out <> "<empty>"
}
out <> text
}
We use chan here so we can return early: linking out <> "<empty>" ends the
process immediately.
A common style is to use a single-condition if as a guard:
dec LogNonEmptyOk : [Result<String, String>] !
def LogNonEmptyOk = [result] chan exit {
if not result is .ok str or str == "" => { exit! }
Debug.Log(str)
exit!
}
Read it as: “if the input is bad, exit; otherwise, str is bound and safe to
use”.
Omitting else in if { ... }
The multi-branch if { ... } form may omit else only if the conditions are
exhaustive. This is checked by types.
For example, this works because cmp has type Ordering:
let cmp = Data.Compare((x) y) in
if {
cmp is .less! => "less",
cmp is .equal! => "equal",
cmp is .greater! => "greater",
}
if {
list is .item(x) xs => { ... }
list is .end! => { ... }
}
In process syntax, code after the if { ... } is still just a fallthrough, not
an implicit else.
The exhaustiveness checking in
ifcurrently isn’t perfect, and won’t correctly handle more complex combinations.
Wrap-up
- Expression
if { ... }returns a value. ismatches aneitherand always includes a payload pattern.and/or/notshort-circuit and carry bindings fromisthrough the paths.- Standalone boolean expressions keep their bindings local.
- In process syntax, multi-branch
if { ... }falls through. - The single-condition process form also uses the following code as an
else.
Pipes
Pipes are a piece of syntax sugar that keep a chain of operations readable. They do not add new behaviour to Par. They just let you write the “do this, then that” story from left to right without inventing throwaway names.
A first taste
Here are some helper functions that operate on numbers:
module Main
import @core/Nat
def Add = [m: Nat, n: Nat] m + n
def Double = [n: Nat] n + n
def Square = [n: Nat] n * n
Without pipes you call them inside one another:
let result = Square(Add(3, Double(4))) // = 196
With pipes you can say the same thing in the order you want to read it:
let result = 3
-> Add(Double(4))
-> Square
The pipe feeds the value on the left into the first argument of the function on the right. Nothing else changes — the two version above do the exact same thing.
Expression semantics
Whenever you see
value -> Func(args)
read it as
Func(value, args)
It helps to think of ->Func as one of the operations in the sequence, just
like (args) or .case { ... }. You can even rewrite the earlier example as
value ->Func (args) to make this explicit.
Account.Lookup(name)
->Auth.Check
.case {
.ok user => user.balance
.err _ => 0
}
If you need to push the value into a later argument, wrap the call in braces so the whole expression becomes the operation:
value -> {Func(arg1)}(arg3) // == Func(arg1, value, arg3)
Pipes as commands
In process syntax every command “uses” the variable on its left and stores the result back into that same variable. Pipes follow the same rule, which means you can treat any function as if it were a built-in command.
module Main
import {
@core/List
@core/Option
@core/Nat
}
dec Push : [List<Nat>, Nat] List<Nat>
def Push = [stack, value] .item(value) stack
let stack = *(1, 2, 3)
stack->Push(4)
// exactly the same as: let stack = Push(stack, 4)
Pipes make destructuring commands pleasant too. Take a Pop function that
returns a head and a tail:
dec Pop : [List<Nat>] (Option<Nat>) List<Nat>
def Pop = [list] list.case {
.end! => (.err!) .end!,
.item(x) xs => (.ok x) xs,
}
let numbers = *(10, 20, 30)
numbers->Pop[top]
// top : Option<Nat>
// numbers : List<Nat> -- now *(20, 30)
Again, the command is just a prettier spelling of
let (top) numbers = Pop(numbers).
This is the reason the pipe feeds the first argument: it lets you extend
the familiar value.operation sequences that already exist in the language
without introducing special cases.
Wrapping up
- Pipes keep left-to-right reading order while preserving Par’s evaluation rules. Drop them and you get the original nested calls back.
- They play nicely with the rest of the syntax: mix them with
case,.selections, further commands — anything that already appends to the sequence. - If the first argument is not the one you need, braces give you full control.
Whenever you notice yourself inventing a tmp variable simply to pass it to
another function, try a pipe — it’s often all the ceremony you actually need.
Nondeterminism, Servers & Clients
In an episode of the “Type Theory Forall” podcast, Phil Wadler said:
❝Linear logic is good for the bits of concurrency where you don’t need concurrency.❞
— Phil Wadler, 2025
Thanks Phil, that’s very encouraging.
What Phil — the wonderful researcher and author of the process language Par is based on — is talking about here is nondeterminism and races. Indeed, linear logic and races are like water and oil. The research has been largely unsatisfying, yielding steps in certain directions, but never quite far enough to solve real-world problems in an elegant and obviously correct manner.
Par offers an innovative solution!
What is nondeterminism?
All features of Par that we’ve covered so far are deterministic. Yes, Par is an automatically concurrent language. Independent bits of your program proceed concurrently, without you needing to lift a finger to make it happen. But when it comes to each single piece, the next instruction clearly says who to talk to, and what to say. Decisions are being made, but they only depend on the inputs. If the inputs have the same values, the outcomes will be the same.
But sometimes, quite often in fact, decisions need to be made based on who speaks first. That’s the race, to speak first. A program gathering information from multiple slow sources can’t say “I’ll first listen to A, then to B.” If A takes 30 minutes to produce its first message, while B has already produced 50 of them, the program just won’t work well.
That’s nondeterminism. It’s not determined if I’ll speak to A or B first, it depends! In this case, it depends on timing.
We’re not talking about randomness, or “nondeterministic choice” here. While those fall under the general umbrella of nondeterminism, the randomness can be understood as a part of the program input. The nondeterminism we are interested in here is concerned with timing.
The problem-space of nondeterminism is quite large, but it mainly comes in two kinds:
- Bidirectional communication — That’s when A and B have a channel between them, but either of them can speak first. If A speaks first, B must react, and vice versa. This is useful for preemptive cancellation, implementing chat servers or real-time dashboards without periodic pings, and so on.
- Server and clients — I don’t mean web servers. What I mean is structuring your program as multiple independent agents — clients — that communicate with a central, stateful agent: the server. The server pays attention to one client at a time, but always the one who speaks first.
Par does not solve the first, yet. You can have cancellation, but it has to be cooperative, you can write a chat server, but there’s got to be periodic checks.
Par solves the second: server and clients, while:
- Keeping all the guarantees: no deadlocks, no runtime crashes, no infinite loops.
- Leveraging Par’s types as session types to allow arbitrary communication protocols between the server and the clients.
- Being very simple to understand and reason about!
👉 Just to make sure it’s clear… we’re not talking about web servers here. We’re talking about a concurrent structure, where any number of client agents are communicating with a central server agent, all inside a single program.
The state of the research
When it comes to linear logic — the theory underlying Par — the problem of races is, to my best knowledge, unsolved in research. Here are some papers that shaped my understanding of the problem, and also why they fall short:
- Client-server sessions in linear logic — This paper is spectacularly elegant. It invents coexponentials, which partially solve the client-server communication topology. Unfortunately, the clients are not resumable.
- Concurrency and races in classical linear logic — This is a follow-up paper, which tries to solve the non-resumability of the clients by introducing single input, single output interfaces for clients to communicate with a central server. Unfortunately, it’s not as elegant, and still not expressive enough.
- Safe session-based concurrency with shared linear state — This one is fairly simple, yet surprisingly potent. It introduces a deadlock-safe mutex type, that can be used to safely share a linear resource among independent processes. Unfortunately, it does not extend well to more involved communication protocols.
- Towards races in linear logic — An extremely elegant approach presented with colorful formulas and icons. It fits very well into linear logic, but unfortunately is restricted to servers with a constant number of clients, which finds few use-cases.
Par’s solution here, its poll/submit control structure, can be used to implement everything from the first 3 papers above, and a lot more, with very few ingredients.
The last paper is able to express some invariants that poll/submit cannot (the constant number of clients), but it’s questionable how useful those could be in real-world programs.
Polling & Submitting
How does Par solve this server-client nondeterminism, i.e. a concurrency structure with independent client agents all communicating with a central server agent?
Par does it by introducing a single feature: the poll/submit control structure.
There are no new types; the existing ones are wholly sufficient for specifying communication between the server and client counterparts.
The idea: Pools
Before we dive into the syntax, it’s good to understand the overall idea. Under the surface, the poll/submit control structure works around pools of clients. You can imagine a pool as just a space for objects to hang out. We call them agents or clients, but they’re really just any values.
A single pool has all its clients of the same type.
They hang out there until they’re ready to take an action, that is:
- Sending a value, for a pair type.
- Receiving a value, for a function type.
- Making a choice, for an either type.
- Responding to a choice, for a choice type.
A client ready to take an action is then polled out of the pool and made available to the poller: the server process. Then once the client is served, zero or more clients can be submitted back to the pool, and the polling continues.
poll / submit
Let’s first take a look at the expression version because it’s more natural to work with most of the time.
Here’s the general syntax for a poll expression:
poll(<client-value>, ...) {
<client-variable> => <result-for-non-empty-pool>
else => <result-after-empty-pool>
}
The poll keyword is followed by a list of initial clients enclosed in parentheses. It must contain at least one initial client.
Then, inside curly braces, we have exactly two branches:
- The active branch: Once a client becomes ready, this branch starts and binds the client to the
<client-variable>. This branch must callsubmit. - The
elsebranch: Once the entire pool is depleted, theelsebranch is entered to produce the final result.
Inside the active branch, we must call submit exactly once.
submit(<client-value>, ...)
Unlike poll, it can take zero clients:
submit()
It puts the clients back in the pool, and goes back to polling again.
The submit expression then returns the overall result of its corresponding poll after this point. It’s all very similar to .begin/.loop. Even the treatment of local variables is the same: local variables used by the poll get automatically moved to the next poll iteration at submit.
There are two important restrictions:
- The client type must be
recursive. submitis only allowed on descendants of the client in the active branch. This ensures progress: you can’t loop forever by putting the same client back into the pool unchanged.
Let’s make it all make sense with some examples.
Simple examples
The simplest way to start is to recreate some functions you’d normally implement with .begin/.loop, but use poll/submit instead.
poll/submitis not a replacement for.begin/.loop. One can’t achieve the job of the other and vice versa, only in some situations.
Let’s compute the sum of a list:
module Main
import {
@core/Int
@core/List
}
dec PollSum : [List<Int>] Int
def PollSum = [nums] poll(nums) {
list => list.case {
.end! => submit(),
.item(x) xs => x + submit(xs),
}
else => 0,
}
Breaking it down:
-
poll(nums)Creates a pool containing a single client:
nums. -
list =>The client is activated and assigned to a new variable:
list. -
list.caseJust a normal
.caseexpression. -
.end! => submit()If the list is empty, we do an empty
submit(). That returns the result of the rest of the nextpoll, which in this case will go to theelsebranch. -
.item(x) xs => x + submit(xs),If the list is not empty, we
submit(xs)the remainder of the list back into the pool, and return the sum of the first item with the result of the nextpoll.
That’s very similar to what we’d do with .begin/.loop:
dec Sum : [List<Int>] Int
def Sum = [nums] nums.begin.case {
.end! => 0,
.item(x) xs => x + xs.loop,
}
Instead of xs.loop, we have submit(xs), but there’s another important difference:
In .begin/.loop, we know that we’re done in the .end! branch. For a pool, the end of a client does not mean the end of the pool. That’s why the .end! branch still needs to submit!
Indeed, the PollSum function can be trivially extended to add up all the numbers from two lists!
dec PollSumTwo : [List<Int>, List<Int>] Int
def PollSumTwo = [nums1, nums2] poll(nums1, nums2) {
list => list.case {
.end! => submit(),
.item(x) xs => x + submit(xs),
}
else => 0,
}
All we did was change this:
def PollSum = [nums] poll(nums) {
To this:
def PollSumTwo = [nums1, nums2] poll(nums1, nums2) {
Everything else remains the same.
The empty submit() in the .end! branch now makes sense! Just because one of the lists has ended doesn’t mean there’s no more clients: there’s the other list!
Let’s now merge two lists into one:
dec MergeTwoLists : <a>[List<a>] [List<a>] List<a>
def MergeTwoLists = [left, right] poll(left, right) {
list => list.case {
.end! => submit(),
.item(x) xs => .item(x) submit(xs),
}
else => .end!,
}
It’s the same principle, but instead of adding numbers, we’re building a resulting list.
Note that the order of items in the resulting list will not be fully arbitrary! The remainder of each list enters the pool only after the item before it gets produced, so for example:
MergeTwoLists(*(1, 2, 3), *(4, 5, 6))The result can be any of these:
*(1, 4, 2, 5, 3, 6)*(1, 2, 3, 4, 5, 6)*(4, 5, 6, 1, 2, 3)But not
*(6, 5, 4, 3, 2, 1)!
What about nondeterministically turning a tree into a list?
type Tree<a> = recursive either {
.leaf a,
.node(self) self,
}
Works like a charm:
dec TreeToList : <a>[Tree<a>] List<a>
def TreeToList = <a>[tree] poll(tree) {
tree => tree.case {
.leaf x => .item(x) submit(),
.node(l) r => submit(l, r),
}
else => .end!,
}
The order of the resulting list only depends on the time when the leaf nodes come into existence.
This is the first time we see submit with more than one client:
.node(l) r => submit(l, r),
A .loop can be used any number of times inside a single .begin, but is always applied to exactly one value. On the other hand, submit must be used exactly once inside a poll, but it can be applied to any number of values.
Process syntax
While all of the examples in this chapter use expression syntax, poll/submit is perfectly available in process syntax as well.
// inside a process
poll(client1, client2) {
client => {
// ... handle the client
submit(client)
}
else => {
// ... handle the rest of the process
}
}
Here, poll and submit are control-flow statements, so they don’t “return” anything. The submit statement simply jumps back to its poll, in addition to putting clients back into the pool.
The Fan Pattern
We’ve been able to merge two lists based on the timing of their items:
module Main
import @core/List
dec MergeTwoLists : <a>[List<a>] [List<a>] List<a>
def MergeTwoLists = [left, right] poll(left, right) {
list => list.case {
.end! => submit(),
.item(x) xs => .item(x) submit(xs),
}
else => .end!,
}
And also a tree:
dec TreeToList : <a>[Tree<a>] List<a>
def TreeToList = <a>[tree] poll(tree) {
tree => tree.case {
.leaf x => .item(x) submit(),
.node(l) r => submit(l, r),
}
else => .end!,
}
Merging multiple sources of information this way is great when you need to aggregate from multiple, slow-producing sources into a single stream, where you can react immediately to every bit produced.
What about merging a list of lists?
dec MergeLists : <a>[List<List<a>>] List<a>
def MergeLists = ???
If we want to merge them in the order their items are produced, we run into a problem with poll/submit.
That’s because a pool requires all its clients to be of the same type. But if we put a List<List<a>> into a pool, we get back a List<List<a>>. We still don’t know which of the inner lists to poll from!
We can actually solve this by combining
poll/submitwith.begin/.loop.dec MergeLists : <a>[List<List<a>>] List<a> def MergeLists = <a>[lists] lists.begin.case { .end! => .end!, .item(list) lists => poll(list, lists.loop) { list => list.case { .end! => submit(), .item(x) xs => .item(x) submit(xs), } else => .end!, } }In this solution, the pool contains lists. However, we end up creating a new pool for every single list, essentially ending up with a linked (by
poll) list of pools. It works, but is quite inefficient.
The efficient solution is to transform the List<List<a>> into a structure that is suitable for polling! We call it the fan pattern.
Fans: the homogeneous trees
Why does poll work great for List<a> and Tree<a>, but not for List<List<a>>? It’s because both List<a> and Tree<a> are homogeneous. Here’s what I mean:
type List<a> = recursive either {
.end!,
.item(x) self,
}
type Tree<a> = recursive either {
.leaf a,
.node(self) self,
}
Every self goes back to the same shape. That’s not true for a list of lists! In a List<List<a>>, the outer nodes are:
recursive either {
.end!,
.item(List<a>) self,
}
While the inner nodes (the List<a>) are:
recursive either {
.end!,
.item(a) self,
}
That’s the discrepancy that prevents a clean poll usage.
The fan transformation
To remedy this, we need to transform a List<List<a>> into a more suitable structure. Here’s one that will work:
type ListFan<a> = recursive either {
.end!,
.spawn(self) self,
.item(a) self,
}
There’s no general prescription for designing these: it all depends on the use-case. However, these branches will appear quite frequently:
.end!,
.spawn(self) self,
They allow the structure to dynamically spread into multiple agents, while the other branches handle the behavior of a single one: an individual list in this case.
The transformation is quite simple:
dec ListFan : <a>[List<List<a>>] ListFan<a>
def ListFan = <a>[lists] lists.begin.case {
.end! => .end!,
.item(list) lists => .spawn(
list.begin.case {
.end! => .end!,
.item(x) xs => .item(x) xs.loop,
}
) lists.loop,
}
It consists of two nested recursions.
-
The outer one produces a
.spawnnode for each list. -
The inner one produces an
.itemnode for each item of a list. -
The
.endnode in the resulting fan structure is used in two ways:- To say there will be no more lists.
- To mark an end of a single list.
The consumer of the
ListFan<a>does not need to differentiate between these two.
Importantly, the transformation is on-line: Each part of the input immediately produces a part of the output. As a result, no concurrency or timing information is lost, with Par’s concurrent execution model.
Now, we’re able to implement MergeLists easily:
dec MergeLists : <a>[List<List<a>>] List<a>
def MergeLists = <a>[lists] poll(ListFan(lists)) {
fan => fan.case {
.end! => submit(),
.spawn(l) r => submit(l, r),
.item(x) fan => .item(x) submit(fan),
}
else => .end!,
}
💡 For the theory lovers: The above covers the Client-server sessions in linear logic paper. The coexponentials introduced there can be defined as:
type Cobang = dual ListFan<dual a> type Coquest = List<a>The axiom rule for them is then implemented the same way as the
MergeListsfunction, except taking aListFan<a>directly, instead of aList<List<a>>.
Communicating Both Ways
So far, information only flowed one way: from the clients to the server. What about the other way?
For example, you might want a server that:
- Generates a unique ID upon request from a client.
- Manages a linear resource with clients taking alternating ownership of it.
- Mediates messages between clients that they address to one another.
All of the above require information flowing not just from clients to the server, but from the server to the clients, too. And all of it is doable!
Two things this is not about:
- A server initiating an interaction. With
poll/submit, the client is always the one who initiates an interaction by becoming ready. - Nondeterministic direction of communication. As we learned in the introduction to this section, Par does not support this, at least yet. The types always say which direction is the next one.
Reminder: Construction by destruction
In the previous chapters, we’ve used expression syntax exclusively. But, it’s often useful to switch to process syntax, especially when combining I/O operations with the asynchronous construction of data structures, like lists and trees.
Let’s take the ListFan<a> from the previous chapter.
type ListFan<a> = recursive either {
.end!,
.spawn(self) self,
.item(a) self,
}
We used it for merging List<List<a>>, but nothing prevents us from using it standalone as well:
dec ServeListFan : <a>[ListFan<a>] List<a>
def ServeListFan = ...
The code will be the same as for MergeLists in the previous chapter.
How would we use it now? The expression syntax is obvious:
ServeListFan(
.spawn(.item(1).item(2).end!)
.spawn(.item(3).item(4).end!)
.end!
)
That certainly works, but if we wanted to combine that with some I/O operations, the process syntax would be better. We’ll use the chan to construct a ListFan<a> by destructing its consumer:
ServeListFan(chan server {
server.spawn(chan server {
// I/O anywhere here
server.item(1)
server.item(2)
server.end!
})
server.spawn(chan server {
// I/O anywhere here
server.item(3)
server.item(4)
server.end!
})
server.end!
})
Now it’s more imperative! I’m sure you can imagine doing all kinds of I/O operations between those .item and .end calls.
What’s the type of the server there? It’s the dual of ListFan<a>:
iterative choice {
.end => ?,
.spawn(dual self) => self,
.item(a) => self,
}
The above is the type of the server from the point of view of the client.
For a small recap from the duality chapter:
-
The
?— the continuation type — is an obligation to dispose of all your resources and finish.A client in the server-client setup must finish before the server does. That follows from the basic principle of Par’s concurrency model: processes connected by their channels form a single tree. It ensures no deadlocks, and no leaking of processes.
-
The signature of
.spawnwith the(dual self) => self, is just the dual version of what we saw previously:.spawn(self) selfThere we saw the server’s point of view, but now we’re looking at the client’s side.
Now back to communicating both ways!
Example: Giving out unique IDs
Suppose we want to spawn a couple of clients and have each of them get a unique ID. Here’s a possible interface from the client’s point of view:
type IdServer = iterative choice {
.end => ?,
.spawn(dual self) => self,
.getId => (Nat) self,
}
Since the clients have to be
recursive, the servers will beiterativefrom the clients’ point of view.
Here’s the dual type from the server’s point of view:
// = dual IdServer
type IdClient = recursive either {
.end!,
.spawn(self) self,
.getId [Nat] self,
}
It’s very similar to what we saw previously, except the .getId variant isn’t giving out a value, it’s taking one.
Here’s how we can implement such a server, with comments:
module Main
import @core/Nat
dec ServeIds : [IdClient] !
def ServeIds = [clients] do {
// Initialize the internal state of the server.
// Here it's just an `id` variable that will keep
// getting incremented.
let id = 0
} in poll(clients) {
client => client.case {
// Standard handling of the fan structure.
.end! => submit(),
.spawn(l) r => submit(l, r),
// A client is requesting an ID.
.getId client => do {
// Increment the `id` variable in-place.
id += 1
// The `client`'s type is `[Nat] IdClient` here.
// We send it a fresh ID using the send command.
client(id)
} in submit(client),
}
else => !
}
Notice how the
idvariable gets implicitly passed to each new iteration atsubmit. The treatment of local variables inpoll/submitis the same as it is with.begin/.loop. They’re kept around, always keeping their latest values.
And here’s how we can use it:
module Main
import {
@core/Debug
@core/Nat
@core/String
}
def SimpleClient: [String] IdClient = [name]
// `IdServer` and `IdClient` are dual, so we can construct
// an `IdClient` by operating on an `IdServer`.
chan server: IdServer {
server.getId[id]
Debug.Log(`${name} got number #{id}`)
server.end!
}
def Main: ! = ServeIds(chan server {
server.spawn(SimpleClient("A"))
server.spawn(SimpleClient("B"))
server.spawn(SimpleClient("C"))
server.spawn(SimpleClient("D"))
server.end!
})
Running this particular program will almost invariably assign the number 1 to A, 2 to B, 3 to C, and 4 to D. That’s just because the clients immediately ask for their ID. If they did any work before asking for it, or were asking multiple times, the results would’ve been different.
The point is, they can run independently, ask for an ID at any point, and get a fresh one every time.
Example: Sharing a resource
We can use the synchronous nature of the server to give out unique access to a shared resource.
- Initially, the server holds the resource.
- A client can request it, and the server gives it out.
- The exclusive session of the server with the client lasts until the client gives the resource back.
- The client gives it back, and then another client can take it.
- Once all clients finish, the resource is returned to the creator of the server.
Here’s a possible interface from the client’s point of view:
type MutexServer<a> = iterative choice {
.end => ?,
.spawn(dual self) => self,
.take => (a) choice {
.put(a) => self,
}
}
Let’s break down the .take method:
-
.take => (a) choice {First, we directly obtain an
avalue, but the server itself turns into a newchoice, with just one method. -
.put(a) => self,The method is
.put, which requires anavalue back. After that, the server returns to the original protocol.
The exclusive session between a client and the server will last until the client puts the value back.
To implement such a server, we need to decide what to do with the value once all clients finish. Here, we just return it to the creator of the server.
type MutexClient<a> = dual MutexServer<a>
dec ShareMutex : <a>[a] [MutexClient<a>] a
def ShareMutex = <a>[value] [clients] poll(clients) {
client => client.case {
.end! => submit(),
.spawn(l) r => submit(l, r),
.take session => session(value).case {
.put(value) client => submit(client),
}
}
else => value,
}
A closer look on this part:
.take session => session(value).case {
.put(value) client => submit(client),
}
After choosing .take, the client (bound as session) becomes this function:
[a] either {
.put(a) MutexClient<a>,
}
We send it the current value, and then use .case to wait until the client gives us the value back. After that, we just submit the client back to the pool.
Using such a server could look like this:
dec IncrementingClient : [Nat] MutexClient<Nat>
def IncrementingClient = [count] chan server {
Nat.Repeat(count).begin.case {
.step rest => {
server.take[n]
n += 1
server.put(n)
rest.loop
}
.end! => {
server.end!
}
}
}
def Main: ! = do {
let final = ShareMutex(0, chan server {
server.spawn(IncrementingClient(1000))
server.spawn(IncrementingClient(1000))
server.spawn(IncrementingClient(1000))
server.end!
})
Debug.Log(`#{final}`)
} in !
We spawn 3 clients, each of which will take, increment, and put the value back a 1000 times. In the end, the value 3000 will be printed.
💡 For the theory lovers: The
MutexServerabove covers the Safe session-based concurrency with shared linear state paper.The remaining one of the three papers that
poll/submitsubsumes — Concurrency and races in classical linear logic — is all about servers like this:type Server = iterative choice { .end => ?, .spawn(dual self) => self, .method1(A1) => (B1) self, .method2(A2) => (B2) self, ... }Those are clearly covered by
poll/submitas well!
Example: A chat server in the Playground
Here’s a more involved example of both-ways communication between a server and its clients. It’s a little toy chat server that you can play with in the Par’s interactive playground.
It’s an example of client-to-client mediation via a server.
You can find a thoroughly commented code for this toy chat server in the examples directory.
Switching Modes With repoll
Sometimes a server needs to “switch gears”.
For example, imagine merging a bunch of cancelable streams into a single cancelable stream:
- While the merged stream is being consumed, the server should keep pulling items from the sources.
- But if the consumer decides to cancel the merged stream, all underlying sources must be canceled too.
This is exactly the kind of situation repoll is for: it lets a server keep the same pool, but start polling it with a different handler.
A cancelable stream: Source<a>
To talk about cancellation, it helps to contrast with List<a>.
Once a List<a> is created, it will keep producing items until it’s done — even if the consumer would prefer to stop early. To make cancellation possible, we can switch to a protocol where the producer and consumer cooperate: the producer can offer work, but the consumer can choose to stop.
Let’s call such a stream-like protocol Source<a>. A first idea might be:
type Source<a> = recursive choice {
.close => !,
.next => either {
.end!,
.item(a) self,
}
}
This is a perfectly valid protocol, but it works poorly with poll: each source is stuck waiting for the server to choose .close or .next, so the sources are not “ready” on their own and we lose most of the concurrency.
A second idea is to let the source produce items first, and only then ask the consumer how to proceed:
type Source<a> = recursive either {
.end!,
.item(a) choice {
.close => !,
.next => self,
}
}
This is closer, but it has an awkward corner when merging: when the consumer of the merged stream decides to .close, the underlying sources may have already produced more as — but we have nowhere to send them.
The solution is to separate “an item is available” from “the item is transferred”:
type Source<a> = recursive either {
.end!,
.item choice {
.discard => !,
.get => (a) self,
}
}
Here, the source can make progress on its own (it can produce .item or .end!), which works great with poll. But when it produces .item, it doesn’t immediately hand out the value — it waits for the consumer to decide:
.getto receive the value and continue..discardto cancel (and the source ends with!).
💡 This is cooperative cancellation: the consumer can only cancel at points where the producer is willing to accept cancellation (here: right after offering
.item).
Switching from “produce” to “cancel”
Now suppose we have many sources, and we want to merge them into one:
dec MergeSources : <a>[List<Source<a>>] Source<a>
When the merged source is canceled, all underlying sources must be canceled too. That means our server needs two distinct modes:
- Normal mode: pull items from ready sources and emit them downstream.
- Cancel mode: stop pulling items and instead discard every remaining source.
This mode switch is what repoll expresses.
repoll
repoll looks like poll, but it does not create a new pool. Instead, it reuses the pool of the nearest enclosing poll (if any), optionally adds some clients into it, and starts polling it with a new handler.
poll(...) {
client => ... repoll(...) {
client => ...
else => ...
}
else => ...
}
It can only be used inside an active branch of a poll, or another repoll.
Example: Merging cancelable sources
We’ll reuse the same fan idea from the fan pattern, but now for Source<a>:
type Source<a> = recursive either {
.end!,
.item choice {
.discard => !,
.get => (a) self,
}
}
type SourceFan<a> = recursive either {
.end!,
.spawn(self) self,
.item choice {
.discard => !,
.get => (a) self,
}
}
dec SourceFan : <a>[List<Source<a>>] SourceFan<a>
def SourceFan = <a>[sources] sources.begin.case {
.end! => .end!,
.item(source) sources => .spawn(source) sources.loop,
}
Now we can implement:
dec MergeSources : <a>[List<Source<a>>] Source<a>
The key idea is that MergeSources has two modes:
- Normal mode: keep producing items by polling sources.
- Cancel mode: once the consumer cancels, discard everything left in the pool.
Here’s the overall structure:
def MergeSources = <a>[sources] poll(SourceFan(sources)) {
fan => fan.case {
.end! => submit(),
.spawn(l) r => submit(l, r),
.item s => .item case {
.discard => ... // switch into cancel mode
.get => ... // produce one item and keep going
}
}
else => .end!,
}
Normal mode: produce items
In the .item branch, the current polled source has offered an item and is now waiting for the consumer’s decision.
If the consumer chooses .get, we request the value from the source, emit it, and submit the source back into the pool:
.get => do { s.get[x] } in (x) submit(s),
Read it left to right:
s.get[x]asks the current source for thea.(x)produces the item from the mergedSource<a>.submit(s)puts the source back, so it can produce again later.
Cancel mode: discard everything left
If the consumer chooses .discard, we must cancel:
- The current source
s(which is in our hands right now). - Every other source still sitting in the pool.
We discard the current source immediately:
let ! = s.discard in ...
Then we switch gears using repoll() (with no extra clients), reusing the same pool but changing the handler to “discard everything”:
.discard => let ! = s.discard in repoll() {
fan => fan.case {
.end! => submit(),
.spawn(l) r => submit(l, r),
.item s => let ! = s.discard in submit(),
}
else => !,
}
This repoll() does not produce any a values. It just drains the pool by discarding sources until it’s empty, and then returns !.
Full code
Putting it all together:
module Main
import @core/List
dec MergeSources : <a>[List<Source<a>>] Source<a>
def MergeSources = <a>[sources] poll(SourceFan(sources)) {
fan => fan.case {
.end! => submit(),
.spawn(l) r => submit(l, r),
.item s => .item case {
.discard => let ! = s.discard in repoll() {
fan => fan.case {
.end! => submit(),
.spawn(l) r => submit(l, r),
.item s => let ! = s.discard in submit(),
}
else => !,
}
.get => do { s.get[x] } in (x) submit(s),
}
}
else => .end!,
}
Labels on
poll/repoll/submit: You can optionally writepoll@label(...),repoll@label(...), andsubmit@label(...).Labels select which poll-point a
submitcontinues at when there are multiple poll-points in scope (created byrepoll).A missing label is itself a label:
submit(...)targets the nearest unlabeled poll-point, whilesubmit@x(...)targets a poll-point labeled@x.